Top các câu chuyện trên Hacker News ngày 14-06-2025 #
- GCP đã gặp sự cố kéo dài 7 giờ 27 phút vào ngày 13 tháng 6 năm 2025, ảnh hưởng đến 52 sản phẩm và 58 khu vực, có thể do lỗi của dịch vụ nội bộ Chemist gây ra và lan sang các dịch vụ bên thứ ba phụ thuộc vào GCP.
- Việc xác thực lại thường xuyên không cải thiện tính bảo mật, có thể dẫn đến gián đoạn quy trình làm việc và sự mệt mỏi khi xác thực đa yếu tố, bảo mật nên được thực hiện thông qua quản lý quyền truy cập hiệu quả và các chính sách phản ứng nhanh.
- Bộ cấp phát bộ nhớ Jemalloc đã trải qua ba giai đoạn phát triển chính kể từ khi ra đời vào năm 2004, giải quyết thành công vấn đề phân mảnh và đạt được những thành tựu đáng kể về hiệu suất, nhưng sự phát triển đã chậm lại trong thời kỳ Meta.
- Nếu Mặt trăng chỉ có một pixel, mô hình Hệ Mặt Trời thể hiện sự rộng lớn của vũ trụ, tốc độ ánh sáng có vẻ chậm trên quy mô vũ trụ, nhận thức của con người về vũ trụ bị giới hạn bởi quy mô và sự trao đổi chất của chính họ.
- Bằng cách raster hóa trực tiếp các đường cong glyph, việc hiển thị văn bản rõ ràng theo thời gian thực trên GPU đã được thực hiện, giải quyết các vấn đề về khử răng cưa sub-pixel và hiển thị chất lượng cao.
- Meta đã đầu tư 14,3 tỷ đô la để khởi động phòng thí nghiệm siêu trí tuệ, tăng cường sức mạnh của mình trong lĩnh vực trí tuệ nhân tạo, cho thấy bố cục chiến lược và quyết tâm cạnh tranh của mình trong lĩnh vực AI.
- Cloudflare đã gặp sự cố dịch vụ do sự cố của dịch vụ Workers KV quan trọng, có thể liên quan đến lỗi của dịch vụ bên thứ ba, sự cố đã được khôi phục nhưng vẫn đang theo dõi tính ổn định của nền tảng.
- OxCaml là một phần mở rộng của ngôn ngữ lập trình OCaml, tập trung vào tối ưu hóa hiệu suất, đặc biệt là về đồng thời và quản lý bộ nhớ, phù hợp cho các tình huống ứng dụng hiệu suất cao, nhưng vẫn đang trong giai đoạn thử nghiệm.
- Một số đế chế công nghệ quảng cáo giả mạo sử dụng CAPTCHA giả mạo và thông báo đẩy để truyền bá thông tin sai lệch, vượt qua kiểm duyệt nội dung của các nền tảng truyền thông xã hội, gây ra mối đe dọa an ninh mạng.
- Một ứng dụng khách BitTorrent được viết từ đầu bằng ngôn ngữ Go đã triển khai các chức năng cốt lõi, bao gồm phân tích tệp torrent và giao tiếp ngang hàng, dự kiến sẽ thêm hỗ trợ liên kết từ tính và DHT.
Sự cố ngừng hoạt động GCP #
GCP Outage
https://status.cloud.google.com/
Trang này là trang trạng thái dịch vụ của Google Cloud, cung cấp thông tin trạng thái của các dịch vụ Google Cloud. Người dùng có thể xem trạng thái hiện tại của các dịch vụ tại đây và liên hệ bộ phận hỗ trợ nếu gặp sự cố không được liệt kê. Trang này cũng cung cấp một liên kết FAQ để tìm hiểu thêm về thông tin được đăng trên bảng điều khiển và có thể truy cập trang web chính thức của Google Cloud để biết thêm thông tin về các dịch vụ này.
Trang hiển thị một sự cố gần đây, xảy ra vào ngày 13 tháng 6 năm 2025, được cập nhật lúc 18:00 PDT, kéo dài 7 giờ 27 phút và đã được đóng. Sự cố này ảnh hưởng đến nhiều sản phẩm GCP, bao gồm API Gateway, Agent Assist, AlloyDB for PostgreSQL, v.v. với tổng cộng 52 sản phẩm, cũng như 58 khu vực như africa-south1, asia, asia-east1, v.v. Người dùng có thể xem lịch sử sự cố.
Trang cũng cung cấp chức năng kiểm tra trạng thái theo sản phẩm và khu vực. Người dùng có thể kiểm tra trạng thái của một khu vực cụ thể và đa khu vực bằng cách nhấp vào các tab khác nhau. Các dịch vụ đa khu vực do Google quản lý để đảm bảo tính dự phòng và phân phối ở nhiều khu vực trong một khu vực địa lý lớn. Trạng thái dịch vụ toàn cầu đề cập đến trạng thái của các dịch vụ phân phối toàn cầu cụ thể và không liên quan đến tất cả các dịch vụ sản phẩm trên toàn cầu.
HN | Độ nóng: 1429 điểm | 491 bình luận | Tác giả: thanhhaimai #
https://news.ycombinator.com/item?id=44260810
- Sự cố gián đoạn của Google Cloud Platform (GCP) có thể là do lỗi của một dịch vụ trung tâm nội bộ của Google có tên là Chemist.
- Firebase Auth và FCM cũng có thể bị ảnh hưởng.
- Không chỉ GCP, nhiều dịch vụ internet cũng bị gián đoạn.
- Sự cố gián đoạn của Cloudflare có thể là do phụ thuộc vào một dịch vụ quan trọng của bên thứ ba của Google.
- Cơ sở hạ tầng của Cloudflare có thể thiếu tính dự phòng vì nó phụ thuộc vào GCP.
- Các nhà cung cấp dịch vụ đám mây nên giảm sự phụ thuộc lẫn nhau.
- Cloudflare có thể nghĩ rằng cơ sở hạ tầng của họ là độc lập, nhưng có thể sẽ đánh giá lại sau sự cố này.
- Ngay cả khi có dự phòng, cũng không thể đảm bảo hoàn toàn miễn nhiễm với lỗi.
- Có người cho rằng Google là một công ty chủ yếu dựa vào quảng cáo, không nên dựa vào nó cho bất kỳ nhiệm vụ quan trọng nào không liên quan đến doanh thu quảng cáo.
- Amazon được coi là một công ty dịch vụ đám mây, AWS quan trọng hơn hoạt động kinh doanh bán lẻ.
- Thật đáng ngạc nhiên khi Cloudflare không có cơ sở hạ tầng riêng, vì nó là một nhà cung cấp dịch vụ internet quy mô lớn.
- Điện toán phi biên (non-edge computing) của Cloudflare có thể hoàn toàn phụ thuộc vào các dịch vụ đám mây của đối thủ cạnh tranh như GCP.
- Mô hình kinh doanh chính của Cloudflare là B2B, phụ thuộc vào một số ít khách hàng có giá trị cao, do đó không có lý do chiến lược để tránh phụ thuộc vào các dịch vụ đám mây như Google.
Yêu cầu xác thực lại thường xuyên không làm bạn an toàn hơn #
Frequent reauth doesn’t make you more secure
https://tailscale.com/blog/frequent-reath-security
Bài viết này thảo luận về ảnh hưởng của việc xác thực lại thường xuyên đối với bảo mật và giải thích tại sao cách làm này có thể phản tác dụng. Bài viết được viết bởi Avery Pennarun, ông chỉ ra rằng việc liên tục nhắc đăng nhập không chỉ làm gián đoạn quy trình làm việc, khiến người dùng cảm thấy khó chịu mà còn thực sự có thể làm suy yếu tình hình bảo mật.
Bài viết bắt đầu bằng cách mô tả một tình huống phổ biến: người dùng đang tập trung làm việc thì phiên làm việc đột ngột hết hạn và cần phải nhập lại mật khẩu và hoàn thành xác thực đa yếu tố (MFA). Thao tác lặp đi lặp lại này không chỉ gây phiền toái mà còn khiến sự mệt mỏi với MFA trở thành một vectơ tấn công lừa đảo ngày càng tăng do số lượng yêu cầu MFA hợp pháp tăng lên. Tác giả chỉ ra rằng trước đây mọi người cho rằng việc thay đổi mật khẩu và đăng nhập thường xuyên là biện pháp bảo mật tốt, nhưng giờ đây người ta nhận thấy sự thật không phải vậy.
Bài viết nhấn mạnh rằng bảo mật không nằm ở tần suất đăng nhập mà nằm ở cách quản lý quyền truy cập hiệu quả, cách phản ứng nhanh chóng với các thay đổi chính sách tài khoản và cách chắc chắn rằng khóa của người dùng không bị lộ kể từ lần xác thực cuối cùng. Bài viết đề cập rằng có thể đạt được sự đảm bảo an toàn mạnh mẽ mà không khiến người dùng cảm thấy khó chịu.
Tiếp theo, bài viết khám phá hai khía cạnh mà xác thực thường kiểm tra: người dùng có còn sở hữu thiết bị vật lý hay không và người dùng có phải là đúng người hay không. Các nhà cung cấp danh tính (IdPs) chủ yếu tập trung vào danh tính người dùng, trong khi các hệ thống xác thực tích hợp như Face ID và Touch ID của Apple, cũng như các công cụ như Windows Hello, đồng thời kiểm tra cả hai.
Bài viết giải thích lý do tại sao việc đăng nhập lại thường xuyên tồn tại: thường là do quản trị viên không chắc chắn rằng các thay đổi sẽ có hiệu lực ngay lập tức. Đôi khi, đặc biệt là trong cấu hình SAML, IdP được cấu hình để chỉ gửi các thuộc tính chính sách cho ứng dụng trong quá trình đăng nhập tương tác của người dùng, điều này có nghĩa là họ cần đăng nhập mới để cập nhật. Bài viết đưa ra rằng việc đăng nhập thường xuyên không phải là câu trả lời đúng, vì chúng giải quyết sai vấn đề, tạo cơ hội cho kẻ tấn công đánh cắp thông tin đăng nhập và hệ điều hành hiện đại đã giải quyết vấn đề này bằng cách khóa màn hình.
Bài viết cũng đề cập rằng việc hết hạn phiên trang web hầu như không cung cấp bất kỳ sự bảo vệ nào, đối với hầu hết mọi người, đây chỉ là tàn tích của thời đại trước. Bài viết khuyên rằng cách xử lý bảo mật đúng đắn nên là kiểm tra quyền sở hữu thiết bị vào những thời điểm quan trọng, sử dụng xác thực liên tục thay vì đăng nhập thường xuyên. Ví dụ: chế độ kiểm tra của Tailscale SSH và Tailscale Slack Accessbot chỉ xác minh sự hiện diện của người dùng khi thực sự quan trọng, thay vì dựa trên khoảng thời gian tùy ý. Bài viết nhấn mạnh rằng bảo mật nên liên tục, thay vì gắn liền với chu kỳ tương tác tùy ý.
Cuối cùng, bài viết kết luận rằng việc đăng nhập thường xuyên không làm bạn an toàn hơn, chúng chỉ khiến bạn hình thành những thói quen bảo mật tồi tệ hơn. Bảo mật tốt nhất là bảo mật diễn ra âm thầm trong nền, đảm bảo an toàn mà không gây cản trở. Tailscale tin rằng bảo mật nên có khả năng thích ứng, thông minh và thực sự hữu ích, chứ không chỉ là trình diễn bảo mật. Tailscale đảm bảo xác thực vào đúng thời điểm với mức độ ma sát tối thiểu, thay vì buộc người dùng phải đăng nhập vô nghĩa.
HN | Độ nóng: 1134 điểm | 478 bình luận | Tác giả: ingve #
https://news.ycombinator.com/item?id=44261777
- Việc đặt lại mật khẩu thường xuyên không làm cho tài khoản an toàn hơn, mà ngược lại có thể khiến người dùng bị khóa tài khoản vào những thời điểm như kỳ nghỉ, và cần liên hệ với bộ phận IT để đặt lại mật khẩu.
- Nhiều công ty vẫn thực thi chính sách hết hạn mật khẩu, mặc dù NIST và Microsoft đã không khuyến nghị cách làm này.
- Yêu cầu về độ phức tạp của mật khẩu thường đến từ yêu cầu kiểm toán, chứ không phải từ bộ phận IT, vì như vậy có thể giảm chi phí bảo hiểm hoặc chi phí xử lý thẻ tín dụng.
- Một số chính sách mật khẩu có thể là để cung cấp bằng chứng trong trường hợp xảy ra rò rỉ dữ liệu, chứng minh rằng công ty đã cố gắng hết sức để thực hiện các biện pháp an ninh.
- Một số chính sách mật khẩu có thể đến từ yêu cầu của chính sách bảo hiểm an ninh mạng.
- Một số chính sách mật khẩu có thể là để tránh phải trả tiền bảo hiểm.
- Quán tính của các hệ thống lớn và sự thất bại của thị trường dẫn đến việc cập nhật chính sách mật khẩu diễn ra chậm chạp.
- Thay đổi chính sách hiện tại có thể mang lại rủi ro trách nhiệm cá nhân, vì vậy người ra quyết định có xu hướng duy trì hiện trạng hơn.
- Một số hệ thống lưu trữ lịch sử mật khẩu cũ để ngăn chặn việc sử dụng lại mật khẩu.
- Một số hệ thống sẽ từ chối mật khẩu mới tương tự như 30 mật khẩu trước đó, điều này có thể dẫn đến danh sách mật khẩu được lưu trữ ở dạng văn bản thuần túy hoặc mã hóa có thể đảo ngược, trở thành mục tiêu của các cuộc tấn công của hacker.
- Bằng cách lưu trữ nhiều phiên bản hash của mật khẩu, có thể phát hiện mật khẩu có bị trùng lặp hay không mà không cần trực tiếp lưu trữ mật khẩu.
- Việc lưu trữ giá trị hash của tất cả các biến thể mật khẩu có thể là không thực tế, vì sự bùng nổ tổ hợp sẽ dẫn đến yêu cầu lưu trữ quá cao.
- Nếu người bảo vệ mật khẩu không yêu cầu nhập mật khẩu cũ, thì họ có thể đã lưu trữ mật khẩu của người dùng.
- Việc thay đổi mật khẩu thường xuyên có thể dẫn đến lỗi hệ thống, chẳng hạn như “broken pipe”.
- Một số hệ thống yêu cầu mật khẩu mới phải khác mật khẩu cũ một số lượng ký tự nhất định.
Jemalloc: Phân tích sau sự cố #
Jemalloc Postmortem
https://jasone.github.io/2025/06/12/jemalloc-postmortem/
Đánh giá về trình cấp phát bộ nhớ jemalloc
Trình cấp phát bộ nhớ jemalloc đã được sử dụng công khai khoảng 20 năm kể từ khi ra đời vào đầu năm 2004. Do tính chất của giấy phép phần mềm nguồn mở, jemalloc sẽ có sẵn công khai vô thời hạn. Nhưng quá trình phát triển thượng nguồn tích cực đã kết thúc. Bài viết này mô tả ngắn gọn các giai đoạn phát triển của jemalloc, mỗi giai đoạn có một số điểm nổi bật thành công và thất bại, sau đó đưa ra một số bình luận hồi tưởng.
Giai đoạn đầu tiên: Lyken Năm 2004, tác giả bắt đầu phát triển ngôn ngữ lập trình Lyken trong bối cảnh tính toán khoa học. Lyken cuối cùng đã đi vào ngõ cụt, nhưng trình cấp phát bộ nhớ thủ công của nó đã hoàn thiện chức năng vào tháng 5 năm 2005. (Bộ thu gom rác dự kiến tận dụng các tính năng của nó chưa bao giờ được hoàn thành.) Vào tháng 9 năm 2005, tác giả bắt đầu tích hợp trình cấp phát vào FreeBSD, và vào tháng 3 năm 2006, tác giả đã loại bỏ trình cấp phát khỏi Lyken và thay thế bằng một lớp bao bọc mỏng các chức năng trình cấp phát hệ thống.
Tại sao phải loại bỏ trình cấp phát bộ nhớ khỏi Lyken sau khi đã nỗ lực rất nhiều? Sau khi trình cấp phát được tích hợp vào FreeBSD, rõ ràng là tính năng duy nhất mà trình cấp phát hệ thống thiếu là cơ chế theo dõi lượng cấp phát để kích hoạt thu gom rác cho mỗi luồng. Điều này có thể được thực hiện bằng cách sử dụng dữ liệu dành riêng cho luồng và một lớp bao bọc mỏng dlsym(3). Thật thú vị, nhiều năm sau, jemalloc thậm chí còn thêm tính năng thu thập thống kê mà Lyken yêu cầu.
Giai đoạn thứ hai: FreeBSD Quay trở lại năm 2005, quá trình chuyển đổi sang máy tính đa xử lý đang diễn ra. FreeBSD có trình cấp phát bộ nhớ phkmalloc xuất sắc của Poul-Henning Kamp, nhưng trình cấp phát này không cung cấp bất kỳ quy định nào cho việc thực thi luồng song song. Trình cấp phát của Lyken dường như là một cải tiến khả năng mở rộng rõ ràng, và được bạn bè và đồng nghiệp khuyến khích, tác giả đã tích hợp trình cấp phát mà sau này sẽ được gọi là jemalloc. Tuy nhiên, ngay sau đó, rõ ràng là jemalloc gặp vấn đề phân mảnh nghiêm trọng trong một số tải nhất định, đặc biệt là tải do các ứng dụng KDE gây ra. Ngay khi tôi nghĩ rằng mình gần như đã hoàn thành, thất bại trong thế giới thực này đã đặt ra câu hỏi về tính khả thi của jemalloc.
Tóm lại, vấn đề phân mảnh bắt nguồn từ việc sử dụng phương pháp cấp phát phạm vi thống nhất (tức là không có sự cô lập lớp kích thước). Tác giả đã lấy cảm hứng cơ bản từ dlmalloc của Doug Lea, nhưng đã không tránh được nhiều phương pháp heuristic đã được kiểm chứng trong thực tế, được lồng vào nhau của các vấn đề phân mảnh tồi tệ nhất. Sau đó, một lượng lớn nghiên cứu và thử nghiệm đã được thực hiện. Vào thời điểm jemalloc trở thành một phần của bản phát hành FreeBSD, thuật toán bố cục của nó đã hoàn toàn thay đổi, sử dụng các vùng cách ly kích thước, như được mô tả trong bài báo BSDCan jemalloc năm 2006.
Giai đoạn 2.5: Firefox Vào tháng 11 năm 2007, Mozilla Firefox 3 sắp được phát hành và tình trạng phân mảnh cao là một vấn đề chưa được giải quyết, đặc biệt là trên Microsoft Windows. Do đó, tác giả bắt đầu hợp tác với Mozilla về công việc cấp phát bộ nhớ. Việc chuyển jemalloc sang Linux là không đáng kể, nhưng Windows lại là một vấn đề khác. Mã nguồn jemalloc chuẩn nằm trong thư viện libc của FreeBSD, vì vậy về cơ bản chúng tôi đã phân nhánh jemalloc và thêm mã khả năng di động, chuyển bất kỳ nội dung nào liên quan đến FreeBSD lên thượng nguồn. Toàn bộ triển khai vẫn nằm trong một tệp, điều này làm giảm ma sát bảo trì phân nhánh, nhưng ở giai đoạn phát triển này, độ phức tạp của việc triển khai chắc chắn vượt quá tính hợp lý của một tệp.
Nhiều năm sau, các nhà phát triển Mozilla đã đóng góp đáng kể cho jemalloc thượng nguồn, cố gắng loại bỏ phân nhánh của họ. Thật không may, các điểm chuẩn của Mozilla liên tục cho thấy phiên bản phân nhánh vượt trội hơn phiên bản thượng nguồn. Tôi không biết liệu điều này là do sự thích ứng quá mức với tối ưu cục bộ hay thực sự cho thấy sự suy giảm hiệu suất, nhưng đây vẫn là một trong những nỗi thất vọng lớn nhất của tôi về jemalloc.
Giai đoạn thứ ba: Facebook Khi tác giả bắt đầu làm việc tại Facebook vào năm 2009, anh ấy đã ngạc nhiên khi thấy rằng trở ngại lớn nhất đối với việc sử dụng rộng rãi jemalloc trong cơ sở hạ tầng Facebook là các công cụ. Các dịch vụ nội bộ quan trọng đang ở trong một tình huống khó xử, dựa vào jemalloc để kiểm soát phân mảnh bộ nhớ, nhưng các kỹ sư cần sử dụng các công cụ phân tích heap pprof từ tcmalloc và gperftools để gỡ lỗi rò rỉ bộ nhớ. Chức năng phân tích heap tương thích với pprof đã trở thành tiêu đề của phiên bản jemalloc 1.0.0.
Quá trình phát triển jemalloc đã chuyển sang GitHub và tiếp tục diễn ra lẻ tẻ trong vài năm tiếp theo khi các vấn đề và cơ hội phát sinh. Các nhà phát triển khác bắt đầu đóng góp các tính năng quan trọng. Phiên bản 3.0.0 giới thiệu cơ sở hạ tầng kiểm tra mở rộng và hỗ trợ Valgrind. Các phiên bản 4.x giới thiệu tính năng dọn dẹp dựa trên suy giảm và đo từ xa định dạng JSON. Dòng 5.x chuyển từ “chunks” sang “extents”, mở đường cho việc tương tác tốt hơn với các trang lớn 2 MiB.
Gây tranh cãi hơn, tác giả đã loại bỏ hỗ trợ Valgrind trong 5.0.0 vì nó là một sự phức tạp bảo trì lớn (có nhiều xúc tu ở những nơi tinh tế) và không được sử dụng nội bộ tại Facebook; các công cụ khác như pprof và MemorySanitizer chiếm ưu thế. Tác giả nhận được rất ít phản hồi về hỗ trợ Valgrind, suy ra rằng nó không được sử dụng. Nhìn lại, tình hình dường như không phải vậy. Đặc biệt, ngôn ngữ Rust tích hợp trực tiếp jemalloc vào các chương trình đã biên dịch và tôi nghĩ rằng có một số trùng lặp giữa các nhà phát triển Rust và các nhà phát triển Valgrind. Mọi người đã tức giận.
jemalloc có thể đã bị loại bỏ khỏi các tệp nhị phân Rust sớm hơn quá trình phát triển tự nhiên.
Đo từ xa nội bộ của Facebook thật tuyệt vời, với dữ liệu hiệu suất từ vô số dịch vụ, là một lợi ích to lớn cho việc phát triển trình cấp phát bộ nhớ. Tôi không nghĩ đây là một sự trùng hợp ngẫu nhiên, hai trình cấp phát bộ nhớ nhanh nhất trong thập kỷ qua (tcmalloc và jemalloc) đều được hưởng lợi từ dữ liệu như vậy. Ngay cả những thứ “đơn giản” như tối ưu hóa đường dẫn nhanh cũng dễ thực hiện đúng hơn khi có dữ liệu Linux perf tổng hợp trong tay. Những thứ khó hơn, như tránh phân mảnh, vẫn khó, nhưng nếu hàng ngàn quy trình làm việc khác nhau hoạt động tốt mà không có hồi quy bất thường, thì một thay đổi có thể an toàn. jemalloc đã được hưởng lợi rất nhiều từ việc trở thành một phần của cơ sở hạ tầng Facebook, cả về hiệu suất, khả năng phục hồi và hành vi nhất quán. Ngoài ra, chức năng báo cáo thống kê tích hợp của riêng jemalloc phản hồi trực tiếp môi trường đo từ xa phổ biến này, điều này thường rất có lợi cho cả việc phát triển jemalloc và điều chỉnh/gỡ lỗi các ứng dụng không phải của Facebook, vượt xa những nỗ lực cần thiết để triển khai.
Trong năm cuối cùng của tác giả tại Facebook, anh ấy đã được khuyến khích thành lập một nhóm jemalloc nhỏ để chúng tôi có thể xử lý một số nhiệm vụ lớn nếu không sẽ rất khó khăn. Ngoài những cải tiến hiệu suất chính, chúng tôi còn nhận được kiểm tra tích hợp liên tục và đo từ xa toàn diện. Khi tác giả rời Facebook vào năm 2017, nhóm jemalloc đã tiếp tục thực hiện một vài năm phát triển và bảo trì xuất sắc mà không có sự tham gia của tôi, gần như hoàn toàn dưới sự lãnh đạo của đồng nghiệp đáng kính của tôi, Qi Wang, và từ lịch sử cam kết, nhận được những đóng góp xuất sắc từ nhiều người khác.
Giai đoạn thứ ba: Meta Khi Facebook đổi thương hiệu thành Meta, bản chất của quá trình phát triển jemalloc đã thay đổi rõ rệt. Kỹ thuật cơ sở hạ tầng Facebook đã giảm đầu tư vào các công nghệ cốt lõi và thay vào đó nhấn mạnh lợi tức đầu tư. Điều này thể hiện rõ trong lịch sử cam kết của jemalloc. Đặc biệt, hạt giống của việc phân bổ trang lớn (HPA) theo nguyên tắc đã được gieo từ năm 2016! Công việc HPA tiếp tục trong vài năm, sau đó chậm lại, sau đó đình trệ, vì các điều chỉnh tích tụ chồng lên nhau mà không có cấu trúc lại cần thiết để giữ cho cơ sở mã khỏe mạnh. Quỹ đạo tính năng này gần đây đã sụp đổ. Vì tôi không tham gia chặt chẽ trong những năm gần đây, nên cảm giác đau lòng đã giảm bớt, nhưng do những thay đổi nội bộ gần đây của Meta, chúng tôi không còn ai hướng dẫn sự phát triển lâu dài của jemalloc để đạt được thế hệ…
HN | Độ nóng: 701 điểm | 213 bình luận | Tác giả: jasone #
https://news.ycombinator.com/item?id=44264958
- Jemalloc là trình cấp phát bộ nhớ đa năng có hiệu năng tốt nhất, nhưng TCMalloc lại khó sử dụng, đặc biệt là khi không sử dụng bazel.
- Có người đề xuất hiện đại hóa các cài đặt mặc định trong phiên bản cuối cùng của Jemalloc, chẳng hạn như tắt cài đặt “cache oblivious” và tăng “page size” mặc định.
- Có người đề cập đến việc thực hiện porting trên máy chủ HP Superdome là một trải nghiệm kỳ lạ và bày tỏ sự ngạc nhiên về khả năng sinh lời của HP vào thời điểm đó.
- Bộ xử lý Itanium được chú ý vì kiến trúc độc đáo của nó, nhưng cũng dẫn đến sự suy tàn của SGI.
- Có người bày tỏ sự tiếc nuối về sự suy tàn của SGI và cho rằng sự thất bại của bộ xử lý Itanium có lợi cho kiến trúc ARM và POWER.
- Có người đề cập rằng công nghệ trình biên dịch hiện đại có thể tận dụng kiến trúc Itanium tốt hơn.
- TCMalloc được sử dụng khác biệt đáng kể khi sử dụng bên trong Google so với sử dụng bên ngoài, vì nó giả định các tùy chọn cấu hình Linux cụ thể.
- Các dự án của Google thường khó sử dụng bên ngoài vì chúng được tích hợp sâu với hệ thống của Google.
Nếu mặt trăng chỉ là 1 pixel: Mô hình hệ mặt trời chính xác đến tẻ nhạt (2014) #
If the moon were only 1 pixel: A tediously accurate solar system model (2014)
https://joshworth.com/dev/pixelspace/pixelspace_solarsystem.html
Trang web này là một bài viết khám phá về hệ mặt trời và không gian vũ trụ, thông qua góc nhìn của một chuyến du hành, dẫn dắt người đọc từ Trái Đất, xuyên qua hệ mặt trời, cảm nhận sự rộng lớn và trống trải của vũ trụ.
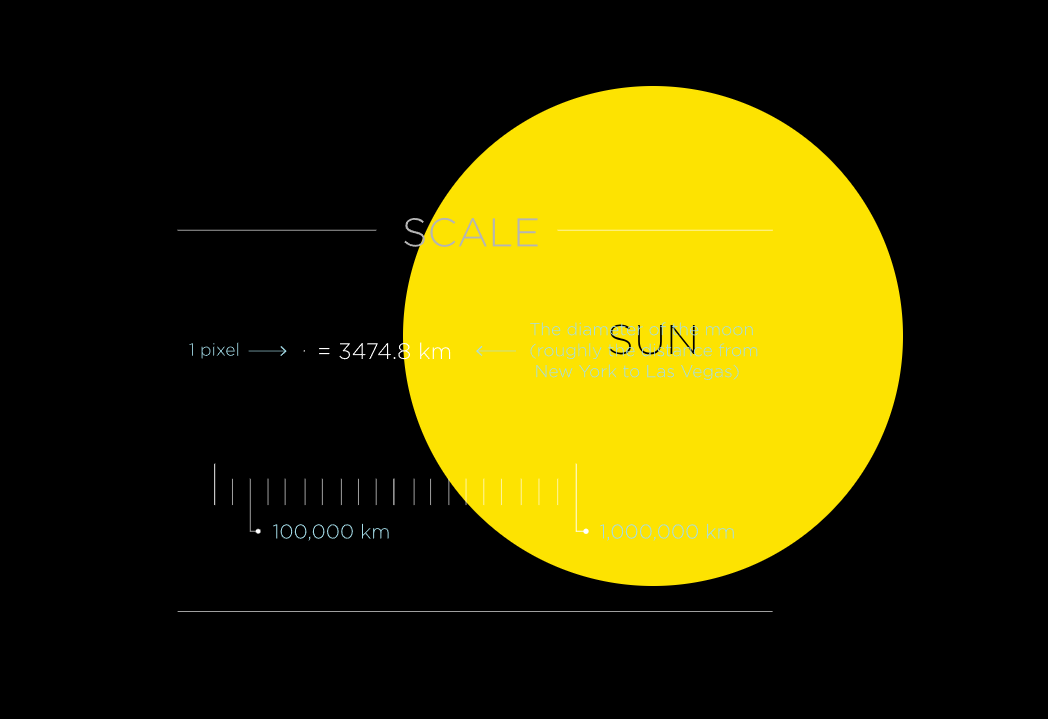
Bài viết bắt đầu từ rìa hệ mặt trời, đề cập đến các hành tinh trong hệ mặt trời, bao gồm Sao Thủy, Sao Kim, Trái Đất, Sao Hỏa, Sao Mộc, Sao Thổ, Sao Thiên Vương và Sao Hải Vương, cũng như Sao Diêm Vương bị hạ cấp thành hành tinh lùn. Tác giả dùng giọng văn hài hước để diễn tả sự trống trải của vũ trụ, đề cập đến việc xuất phát từ Trái Đất, ngay cả đến hành tinh gần nhất, cũng cần phải vượt qua hàng triệu km không gian trống trải.
Bài viết tiếp tục mô tả sự dài dòng và nhàm chán của du hành vũ trụ, đề cập đến việc nếu đi tàu vũ trụ đến Sao Hỏa, có thể mất bảy tháng, và cần 2000 bộ phim để giết thời gian. Tác giả nhấn mạnh rằng phần lớn vũ trụ là không gian trống trải, ngay cả trong hệ mặt trời, khoảng cách giữa các hành tinh cũng rất xa.
Bài viết cũng đề cập đến vấn đề tỷ lệ của hệ mặt trời, chỉ ra rằng hầu hết các bản đồ hệ mặt trời không được vẽ theo tỷ lệ thực tế, vì không gian trống trải thực tế khó thể hiện trên bản đồ. Tác giả đề cập rằng ngay cả trong hệ mặt trời, khoảng cách giữa các hành tinh cũng thay đổi, tùy thuộc vào vị trí của chúng trên quỹ đạo quanh mặt trời.
Bài viết cố gắng giúp độc giả hiểu được sự rộng lớn của vũ trụ thông qua một số phép ẩn dụ và ngôn ngữ hài hước. Ví dụ, nếu coi Trái Đất là một điểm ảnh, thì cần hàng triệu màn hình cạnh nhau để hiển thị bản đồ toàn bộ hệ mặt trời. Nếu in với chất lượng 300 pixel trên mỗi inch, Trái Đất sẽ không nhìn thấy được, và chiều rộng của giấy cần 475 feet, xấp xỉ chiều dài một sân bóng đá rưỡi.
Bài viết cũng khám phá sự khó khăn trong việc cảm nhận những con số khổng lồ và không gian trống trải của con người, đề cập đến việc chúng ta quen với việc xử lý các quy mô nhỏ hơn nhiều so với điều này. Tác giả chỉ ra rằng chúng ta luôn cố gắng tìm những phép ẩn dụ cho những con số lớn, nhưng những phép ẩn dụ này dường như luôn không hiệu quả. Bài viết sử dụng một số ví dụ sinh động, chẳng hạn như giọt nước xói mòn hẻm núi, amip biến thành cá heo, ngôi sao sụp đổ, v.v., để minh họa rằng ngay cả trong quy mô thời gian và không gian khổng lồ, cũng có thể có rất nhiều điều xảy ra.
Bài viết cuối cùng thảo luận về ảnh hưởng tâm lý của “hư vô” trong vũ trụ đối với con người, đề cập đến việc bộ não con người không giỏi xử lý khái niệm “hư vô”. Tác giả dùng ngôn ngữ hài hước để mô tả cách tiến hóa không có thời gian để cung cấp cho con người khả năng xử lý không gian rộng lớn vô tận, vì tiến hóa bận rộn hơn với việc giải quyết các vấn đề sinh tồn khác. Bài viết nhấn mạnh rằng mặc dù chúng ta không thể hiểu đầy đủ những không gian rộng lớn này, nhưng các mô hình toán học và kiến thức khoa học giúp chúng ta xây dựng sự hiểu biết về vũ trụ.
Nói chung, bài viết này thông qua góc nhìn của một chuyến du hành, cho phép độc giả cảm nhận được sự rộng lớn và trống trải của vũ trụ, đồng thời khám phá những hạn chế trong nhận thức và hiểu biết của con người về vũ trụ. Thông qua sự hài hước và ẩn dụ, bài viết giúp độc giả hiểu sâu sắc hơn về sự rộng lớn của vũ trụ, đồng thời suy ngẫm về vị trí và ý nghĩa của con người trong vũ trụ.
HN | Độ nóng: 657 điểm | 212 bình luận | Tác giả: sdoering #
https://news.ycombinator.com/item?id=44266828
- Ở quy mô vũ trụ, tốc độ ánh sáng có vẻ rất chậm, con người có thể sẽ không bao giờ đến được một hành tinh khác.
- Nhận thức của con người về thời gian có thể liên quan đến tốc độ trao đổi chất và kích thước nhỏ bé của chúng ta, trong khi thực vật và các ngôi sao có thể tồn tại ở các thang thời gian khác nhau.
- Từ góc độ của các ngôi sao, những thay đổi sinh thái trên Trái Đất chỉ là một khoảnh khắc trong cuộc đời dài đằng đẵng của chúng.
- Con người có thể chỉ là một sự tồn tại ngắn ngủi trong vũ trụ, trong khi sự sống dựa trên silicon có thể là “trình tự khởi động” của chúng ta.
- Trong mô hình này, tốc độ ánh sáng có vẻ chậm vì nó không xem xét thuyết tương đối hẹp.
- Về mặt lý thuyết, bằng cách di chuyển gần tốc độ ánh sáng, có thể đến bất kỳ đâu trong vũ trụ trong một khoảng thời gian cực ngắn, mặc dù điều này có thể gây ảnh hưởng đến cơ thể của người du hành.
- Ngay cả khi di chuyển với tốc độ 0,5 lần tốc độ ánh sáng, cũng cần vài tháng để đến ngôi sao gần nhất, và đó là còn phải tính đến việc giảm tốc.
- Sự nhỏ bé của con người trong vũ trụ và tốc độ tương đối chậm của ánh sáng khiến việc khám phá vũ trụ trở nên khó khăn.
- Du hành gần tốc độ ánh sáng có thể cho phép người du hành đi qua hàng nghìn năm ánh sáng trong một đời người, nhưng đối với những người ở lại Trái Đất, đó sẽ là hàng nghìn năm.
- Nếu có thể liên tục tăng tốc với gia tốc 1G, về mặt lý thuyết có thể đến trung tâm Ngân Hà hoặc thậm chí cả thiên hà Tiên Nữ trong một khoảng thời gian tương đối ngắn.
- Khi du hành trong vũ trụ, có thể không cần lo lắng về lực cản của không khí, nhưng cần xem xét cách cung cấp liên tục năng lượng cần thiết cho việc tăng tốc.
Kết xuất Văn bản Sắc nét trên GPU #
Rendering Crispy Text on the GPU
https://osor.io/text Bài viết này thảo luận về các kỹ thuật hiển thị văn bản theo thời gian thực, đặc biệt tập trung vào phương pháp hiển thị văn bản rõ nét trên GPU. Tác giả trước đây đã sử dụng trường khoảng cách có dấu đa kênh (SDFs) để hiển thị văn bản, mặc dù hiệu quả tốt, nhưng vẫn còn một số điểm chưa hài lòng, chẳng hạn như khử răng cưa, kích thước texture lớn, thời gian xây dựng chậm, vấn đề về thu phóng và di chuyển mượt mà. Việc tác giả mới mua một màn hình OLED, màn hình này do cấu trúc sub-pixel không chuẩn nên có vấn đề về quầng sáng ở các cạnh, điều này đã thúc đẩy tác giả nghiên cứu lại kỹ thuật hiển thị phông chữ, đặc biệt là khử răng cưa sub-pixel.
Bài viết trước tiên trình bày một số thử nghiệm phông chữ, bao gồm các kiểu khác nhau như tròn trịa, sắc nét, đường nét rất mảnh, v.v., đồng thời cung cấp một liên kết thử nghiệm độ phân giải cao, khuyên bạn nên mở trong một tab mới và xem với tỷ lệ gốc 100%. Ngoài ra còn có một menu hiển thị động, hiển thị hiệu ứng của văn bản khi di chuyển, cũng như bảng điều khiển và văn bản demo đã hiển thị trước đó.
Tác giả đề cập rằng việc hiển thị hình ảnh và video có thể gây ra hiện tượng giả ảnh do các vấn đề như thu phóng, căn chỉnh pixel và cấu trúc sub-pixel. Các vấn đề chính khi sử dụng SDFs bao gồm chất lượng, kích thước atlas, tính linh hoạt và sự đơn giản. Một số phông chữ, đặc biệt là những phông chữ có các đặc điểm mảnh hoặc nhiều chi tiết, cho hiệu quả hiển thị không tốt. SDFs cần một độ phân giải nhất định để có được chất lượng đầu ra tốt, đặc biệt là đối với các phông chữ chứa nhiều glyph, điều này dẫn đến kích thước atlas tăng lên. Ngoài ra, SDFs cần tải nhiều phông chữ trong thời gian chạy, điều này làm tăng chi phí bộ nhớ và băng thông truyền phát. Tác giả cũng đề cập rằng SDFs phức tạp hơn trong việc xử lý thu phóng và triển khai các ý tưởng mới (chẳng hạn như khử răng cưa sub-pixel), và tác giả muốn có thể xử lý bất kỳ hình ảnh vector nào trong thời gian chạy.
Bài viết đề xuất một giải pháp, đó là không “nướng” bất cứ thứ gì vào texture, mà trực tiếp lấy các đường cong của glyph hiện đang hiển thị, gửi chúng đến GPU và thực hiện raster hóa. Phương pháp này có thể giảm nhu cầu lưu trữ, vì không cần phải phân bổ không gian cho mỗi ô glyph trong atlas, và có thể trực tiếp hiển thị biểu diễn vector, do đó có thể duy trì hiệu quả tốt ở bất kỳ độ phân giải nào và tương thích với các kỹ thuật như khử răng cưa sub-pixel.
Giải pháp bao gồm tải trực tiếp dữ liệu đường cong glyph, raster hóa theo thời gian thực vào atlas và lấy mẫu atlas theo yêu cầu để hiển thị glyph hiển thị. Tác giả nhấn mạnh rằng, miễn là glyph tiếp tục được sử dụng trong các khung hình tiếp theo, nó sẽ được giữ lại trong atlas, điều này có thể tích lũy và tinh chỉnh kết quả raster hóa, thậm chí có thể đạt được hiệu ứng khử răng cưa sub-pixel chất lượng rất cao.
Bài viết phác thảo toàn bộ quy trình xử lý, từ tải phông chữ gốc đến hiển thị cuối cùng trên màn hình. Tác giả sử dụng FreeType làm công cụ ngoại tuyến để tải định dạng phông chữ và duyệt qua các đường cong của mỗi glyph, lưu trữ chúng trong định dạng tài sản, sau đó chuyển chúng đến GPU. Glyph có thể chứa đường thẳng, đường cong Bezier bậc hai hoặc đường cong Bezier bậc ba, tác giả chuyển đổi tất cả chúng thành đường cong Bezier bậc hai để đơn giản hóa độ phức tạp của shader. Bài viết cũng thảo luận về cách chuyển đổi đường thẳng và đường cong Bezier bậc ba thành đường cong Bezier bậc hai.
Cuối cùng, bài viết thảo luận về quá trình tính toán độ phủ, không khác biệt nhiều so với các phương pháp có thể tìm thấy ở những nơi khác. Bằng cách phát tia theo chiều ngang trên mỗi pixel, kiểm tra các giao điểm với đường cong và tích lũy một số vòng để xác định xem nó được coi là bên ngoài (không) hay bên trong (khác không). Quá trình này liên quan đến việc giải một phương trình bậc hai. Tác giả giới thiệu hai tài nguyên để giải thích nguyên tắc toán học này: kho lưu trữ GitHub của GreenLightning và video hiển thị văn bản của Sebastian Lague, các tài nguyên này bao gồm các nguyên tắc raster hóa glyph và quá trình cải tiến giải pháp của anh ấy. Nếu độc giả quan tâm đến mã nguồn, những liên kết này cũng có thể cung cấp trợ giúp. Tác giả cũng đề cập rằng bước này có thể gặp sự cố do tính không chính xác của việc tính toán giao điểm.
HN | Độ nóng: 390 điểm | 121 bình luận | Tác giả: ibobev #
https://news.ycombinator.com/item?id=44265233
- Tác giả bày tỏ sự ngạc nhiên và cảm ơn về cuộc thảo luận về bài đăng trên Hacker News.
- Dấu chấm trên chữ “j” in nghiêng trong video đã biến mất.
- Kết xuất phông chữ subpixel rất quan trọng đối với khả năng đọc, nhưng không thể lấy được thông số kỹ thuật bố cục pixel từ các tiêu chuẩn hiển thị hiện có.
- Kết xuất subpixel trên màn hình độ phân giải tiêu chuẩn không phải là “quan trọng” mà là “thêm điểm cộng”; hầu như không cần thiết phải kết xuất subpixel trên màn hình Retina.
- Kết xuất subpixel mang lại nhiều vấn đề, chẳng hạn như ảnh chụp màn hình bị ràng buộc với một bố cục subpixel cụ thể và không thể mở rộng tỷ lệ bitmap, v.v.
- Có người phản đối kết xuất subpixel, cho rằng nó chỉ là một cải tiến tạm thời trong kỷ nguyên LCD.
- Ngay cả trên màn hình không phải Retina, một số người vẫn chưa nâng cấp lên độ phân giải cao hơn vì vấn đề giá cả.
- Màn hình 4K 47 inch rất tuyệt vời để lập trình, nhưng kết xuất subpixel vẫn có giá trị của nó.
- Có người đã mua màn hình 4K cách đây mười năm và bày tỏ sự tiếc nuối về những tổn thất của TV 4K.
- Ngay cả trên màn hình độ phân giải tiêu chuẩn, một số người vẫn thấy các cạnh màu do kết xuất subpixel gây ra.
- Điều chỉnh giá trị gamma hiển thị có thể cải thiện hiệu ứng khử răng cưa subpixel.
- Apple có thể đảm bảo rằng màn hình trong hệ sinh thái của họ có căn chỉnh subpixel cụ thể, nhưng họ vẫn hủy bỏ tính năng này.
- Ở mật độ điểm ảnh cao, các tạo tác do subpixel AA tạo ra là không cần thiết.
- Apple không thể đảm bảo rằng tất cả các màn hình bên ngoài đều có mật độ điểm ảnh đủ cao.
- Có người đặt câu hỏi về số lượng màn hình loại Retina đang được sử dụng trên thị trường.
- Điện thoại hiện đại hầu như đều là màn hình Retina, nhưng máy tính vẫn bị kẹt ở độ phân giải 1080p.
- Có người đề xuất cần một định dạng hình ảnh chụp màn hình tốt hơn để giữ lại vector và văn bản thay vì raster hóa.
Meta đầu tư 14,3 tỷ đô la vào Scale AI để khởi động phòng thí nghiệm siêu trí tuệ #
Meta invests $14.3B in Scale AI to kick-start superintelligence lab
https://www.nytimes.com/2025/06/12/technology/meta-scale-ai.html
Meta (trước đây là Facebook) đã công bố khoản đầu tư 14,3 tỷ đô la Mỹ vào công ty khởi nghiệp Scale AI, đây là khoản đầu tư thiểu số lớn đầu tiên ra bên ngoài của họ. Thương vụ này nhằm mục đích tăng cường sức mạnh của Meta trong lĩnh vực trí tuệ nhân tạo (AI), để đối phó với các đối thủ cạnh tranh ngày càng tăng, bao gồm Google, Microsoft, OpenAI và Anthropic.

Scale AI là một công ty tập trung vào việc cung cấp dữ liệu huấn luyện cho các hệ thống trí tuệ nhân tạo, đóng một vai trò quan trọng đằng sau hậu trường trong sự phát triển của AI. Theo các điều khoản của thỏa thuận, Giám đốc điều hành của Scale AI, Alexandr Wang, sẽ gia nhập Meta và giữ chức vụ điều hành trong “Phòng thí nghiệm Siêu Trí tuệ” mới được thành lập. Wang được coi là một nhà lãnh đạo có tầm nhìn xa trong nội bộ Meta, ông cũng sẽ dẫn dắt một bộ phận nhân viên của Scale AI gia nhập Meta.
Khoản đầu tư này tương đương với khoảng 10% doanh thu năm 2024 của Meta, đồng thời là thương vụ lớn thứ hai của Meta sau thương vụ mua lại WhatsApp với giá 19 tỷ đô la Mỹ vào năm 2014. Meta hy vọng thông qua sự hợp tác chiến lược này, sẽ làm sâu sắc hơn nữa sự hợp tác với Scale AI, để nâng cao năng lực của mình trong việc sản xuất dữ liệu mô hình AI.
Người phát ngôn của Meta cho biết: “Meta đã hoàn thành hợp tác chiến lược và đầu tư vào Scale AI. Là một phần của sự hợp tác này, chúng tôi sẽ làm sâu sắc hơn sự hợp tác trong việc sản xuất dữ liệu mô hình AI, Alexandr Wang sẽ gia nhập Meta và tham gia vào dự án siêu trí tuệ của chúng tôi.” Động thái này cho thấy sự coi trọng của Meta đối với lĩnh vực AI cũng như quyết tâm của họ trong việc bắt kịp các đối thủ cạnh tranh trong công nghệ mang tính chuyển đổi này.
HN | Độ nóng: 388 điểm | 404 bình luận | Tác giả: RyanShook #
https://news.ycombinator.com/item?id=44268197
- Meta đã có hai phòng thí nghiệm AI, chúng cạnh tranh với nhau và đều đang trên bờ vực thất bại.
- Meta gặp khó khăn trong việc tuyển dụng những siêu sao gia nhập GenAI, vì không ai muốn gia nhập một con tàu Titanic sắp chìm.
- Tiềm năng tăng trưởng của OpenAI lớn hơn Meta, ngay cả khi Meta cung cấp lượng lớn tiền mặt và cổ phiếu bồi thường.
- Meta trả mức lương cao từ 7-8 con số, nhưng vấn đề là mọi người đều biết Meta là một nơi hỗn loạn, chỉ thu hút những người chỉ quan tâm đến tiền lương.
- Cổ phần của OpenAI có thời gian chờ (vesting) hiệu lực hơn 2 năm, trong khi Meta trả bằng tiền mặt.
- Meta cần một người như Sam Altman để lãnh đạo, nhằm thúc đẩy kết quả.
- Meta và Scale đều nổi tiếng với văn hóa áp lực cao và đấu đá chính trị, điều này hạn chế sự đổi mới.
- Thời gian bán rã của công nghệ AI tính bằng tháng, và sự nghiệp của nhiều người làm AI có thể rất ngắn ngủi.
- Rob Fergus là một trong những người sáng lập FAIR, việc lãnh đạo FAIR là hợp lý.
- Yann LeCun có vai trò hạn chế tại Meta, ông ấy không thực sự lãnh đạo bất kỳ dự án nào.
- Ngoài các công cụ gắn nhãn dữ liệu, Scale còn xây dựng một lượng lớn bộ dữ liệu độc quyền và cấp phép chúng cho các doanh nghiệp lớn để đào tạo.
- Meta có thể muốn cắt đứt con đường tiếp cận dữ liệu của Scale của các đối thủ cạnh tranh khác bằng cách mua lại Scale.
- OpenAI và Anthropic dựa vào nhiều nhà cung cấp dữ liệu để đảm bảo không có công ty bên ngoài nào biết cách họ đào tạo các mô hình độc quyền của mình.
- Dữ liệu của Scale không phải là tốt nhất, do đó sức hấp dẫn đối với Meta là hạn chế.
- Các công ty khác có thể lấp đầy khoảng trống thị trường mà Scale để lại, do đó việc mua lại của Meta có thể không có hiệu quả thực tế.
- Meta có thể muốn đạt được sự tích hợp theo chiều dọc lớn hơn thông qua thương vụ mua lại này.
Cloudflare đã ngừng hoạt động #
Cloudflare was down
https://www.cloudflarestatus.com/incidents/25r9t0vz99rp
Trang web này là báo cáo về sự cố gián đoạn dịch vụ của Cloudflare xảy ra vào ngày 12 tháng 6 năm 2025. Dưới đây là bản tóm tắt chi tiết bằng tiếng Việt về sự cố này:
- Trạng thái sự cố: Sự cố gián đoạn dịch vụ này đã được giải quyết. Tất cả các dịch vụ của Cloudflare đã khôi phục và hoạt động đầy đủ. Hiện tại, nhóm đang theo dõi các chỉ số nền tảng để xác nhận tính ổn định.
- Tình hình khôi phục dịch vụ: Dịch vụ của Cloudflare đã nhanh chóng khôi phục trên toàn cầu. Dịch vụ WARP và Turnstile đã hoạt động, mặc dù vẫn còn một phần nhỏ ảnh hưởng còn sót lại, nhóm đang nỗ lực loại bỏ. Dịch vụ KV cốt lõi đã khôi phục, các sản phẩm phụ thuộc vào dịch vụ KV đang được đưa trở lại trực tuyến. Dự kiến sẽ có thêm sự phục hồi trong vài phút tới, ảnh hưởng sẽ giảm dần.
- Nguyên nhân gián đoạn dịch vụ: Dịch vụ Workers KV quan trọng của Cloudflare đã ngoại tuyến do sự gián đoạn của một dịch vụ bên thứ ba, dịch vụ bên thứ ba này là một phụ thuộc quan trọng của dịch vụ KV. Do đó, một số sản phẩm của Cloudflare phụ thuộc vào dịch vụ KV để lưu trữ và truyền bá thông tin không khả dụng, bao gồm Access, WARP, Browser Isolation, Browser Rendering, Durable Objects (chỉ hỗ trợ Durable Objects được hỗ trợ bởi SQLite), Workers KV, Realtime, Workers AI, Stream, một phần của bảng điều khiển Cloudflare, Turnstile, AI Gateway và AutoRAG. Các kỹ sư của Cloudflare đang khẩn trương khôi phục dịch vụ và nhận thức được tác động nghiêm trọng do sự gián đoạn này gây ra, đang nỗ lực hết mình để khôi phục tất cả các dịch vụ càng sớm càng tốt.
- Tiến trình khôi phục dịch vụ: Dịch vụ bắt đầu khôi phục, dự kiến vẫn sẽ xảy ra lỗi gián đoạn trong các dịch vụ bị ảnh hưởng, vì hệ thống xử lý việc thử lại và điền vào bộ nhớ cache.
- Các dịch vụ bị ảnh hưởng: Bao gồm Access, WARP, Durable Objects (chỉ hỗ trợ Durable Objects được hỗ trợ bởi SQLite), Workers KV, Realtime, Workers AI, Stream, một phần của bảng điều khiển Cloudflare và AI Gateway, AutoRAG.
- Tiến trình điều tra: Nhóm kỹ thuật của Cloudflare đang điều tra các vấn đề dẫn đến lỗi xác thực Access. Kết nối Cloudflare Zero Trust WARP cũng bị ảnh hưởng.
- Đăng ký cập nhật: Người dùng có thể đăng ký nhận cập nhật về sự cố gián đoạn dịch vụ của Cloudflare qua email và/hoặc SMS. Khi sự cố gián đoạn dịch vụ được cập nhật, người dùng sẽ nhận được thông báo qua email, khi Cloudflare tạo hoặc giải quyết sự cố gián đoạn dịch vụ, người dùng sẽ nhận được thông báo qua SMS.
Bản tóm tắt này cung cấp thông tin chi tiết về sự cố gián đoạn dịch vụ của Cloudflare, bao gồm trạng thái sự cố, tình hình khôi phục dịch vụ, nguyên nhân gián đoạn dịch vụ, tiến trình khôi phục dịch vụ, các dịch vụ bị ảnh hưởng và thông tin liên quan đến đăng ký cập nhật.
HN | Độ nóng: 333 điểm | 86 bình luận | Tác giả: datadrivenangel #
https://news.ycombinator.com/item?id=44261064
- Dịch vụ Workers KV của Cloudflare ngoại tuyến do lỗi của dịch vụ bên thứ ba, một phụ thuộc quan trọng.
- Có người suy đoán Cloudflare phụ thuộc vào GCP (Google Cloud Platform) để cung cấp một phần dịch vụ.
- Có quan điểm cho rằng mối quan hệ phụ thuộc này sẽ không kéo dài lâu.
- Bài viết đề cập đến việc Workers KV đang chuyển sang cơ sở hạ tầng linh hoạt hơn, nhưng sự kiện này đã phơi bày lỗ hổng bao phủ.
- Có người suy đoán 95% cơ sở hạ tầng của công ty Cloudflare có thể phụ thuộc vào dịch vụ này.
- Có tin đồn rằng “sự phụ thuộc bắt buộc” này là để giảm thiểu “rủi ro nội bộ”.
- Có người hỏi ý nghĩa của WAG (wild-assed guess, tức là phỏng đoán vô căn cứ).
- Có người đùa rằng có thể là người dùng đang vẫy đuôi.
- CEO của Cloudflare cho biết sự phụ thuộc này sẽ không kéo dài lâu.
- Có người cung cấp liên kết đến trang con bộ xử lý GDPR của Cloudflare để xác minh mối quan hệ phụ thuộc.
- Có người đề cập rằng Google phủ nhận có bất kỳ sự cố nào.
- Có người cung cấp liên kết đến trang Google Cloud Status, hiển thị có sự cố.
- Có người cho biết khách hàng biết rằng tuyên bố của Google không đúng sự thật.
- Có người đưa ra giả thuyết có thể là trường hợp “100% sự cố ảnh hưởng đến 3% khách hàng”.
- Có người chỉ ra rằng nên liên kết đến bảng điều khiển dịch vụ thực tế của Google, thay vì một tweet từ vài giờ trước.
- Có người đề cập rằng có thể là để tránh thanh toán SLA/SLO (Thỏa thuận mức dịch vụ/Mục tiêu mức dịch vụ).
- Có người đề cập rằng trang web DownDetector hiển thị nhiều công ty lớn, bao gồm Google, CloudFlare, AWS, đều gặp sự cố, có thể là do vấn đề định tuyến BGP lớn.
- Có người đề cập rằng họ không trực tiếp trải qua bất kỳ sự cố nào, họ ở Châu Âu.
- Có người cung cấp một liên kết đến bài viết kỹ thuật về BGP hijacking.
- Có người đặt câu hỏi liệu điều này có liên quan đến sự leo thang căng thẳng ở Israel hay không.
- Có người đề cập rằng báo cáo Pizza của Lầu Năm Góc đã có rất nhiều hoạt động trong 24 giờ qua, có thể là sự trùng hợp ngẫu nhiên.
- Có người đề cập rằng Internet Health Report hiển thị “không có dữ liệu để hiển thị”.
- Có người đề cập rằng Anthropic cũng bị giảm/xuống cấp.
- Có người đề cập rằng GCP cũng gặp sự cố.
- Có người đùa khi sự cố dịch vụ được mở rộng quy mô.
- Có người tò mò liệu Cloudflare có sử dụng GCP hay không.
- Có người cho biết cơ sở hạ tầng xác thực của Cloudflare có thể bị ảnh hưởng bởi sự cố của Google.
- Có người xác nhận rằng bộ nhớ KV của Cloudflare chắc chắn đã gặp sự cố.
- Có người đề cập rằng Google tuyên bố nguyên nhân gốc rễ của sự cố là dịch vụ IAM (Quản lý danh tính và truy cập) trung tâm của họ, điều này sẽ gây ra hiệu ứng dây chuyền cho các dịch vụ khác.
- Có người hỏi thông tin này được xem ở đâu, có phải trên mạng xã hội hay không.
- Có người cung cấp liên kết đến trang Google Cloud Status, hiển thị nhiều sản phẩm GCP bị ảnh hưởng do sự cố dịch vụ IAM.
- Có người chỉ ra rằng phần bình luận này không xuất hiện khi họ trả lời.
- Có người cho biết toàn bộ cơ sở hạ tầng GCP của họ hoạt động bình thường, chỉ là không thể quản lý bất cứ thứ gì.
- Có người chỉ ra rằng nếu nhiều dịch vụ mà họ liệt kê thực sự bị gián đoạn trên diện rộng, thì tình hình sẽ tồi tệ hơn nhiều.
- Có người nhắc nhở rằng, không thể suy luận rằng dịch vụ hoạt động cho tất cả mọi người chỉ vì nó hoạt động cho một người, Google sẽ không liệt kê dịch vụ là bị gián đoạn mà không có lý do.
OxCaml - một tập hợp các mở rộng cho ngôn ngữ lập trình OCaml. #
OxCaml - a set of extensions to the OCaml programming language.
OxCaml là một tập hợp các mở rộng đang phát triển nhanh chóng cho ngôn ngữ lập trình OCaml, nó là trình biên dịch sản xuất của Jane Street, đồng thời cũng là một phòng thí nghiệm thử nghiệm, tập trung vào việc làm cho OCaml phù hợp hơn với lập trình hướng đến hiệu năng. Mục tiêu của OxCaml là hy vọng những mở rộng này cuối cùng có thể đóng góp cho OCaml thượng nguồn.

Mục tiêu thiết kế chính của OxCaml là cung cấp khả năng kiểm soát an toàn, thuận tiện, có thể dự đoán được để tối ưu hóa các khía cạnh hiệu năng quan trọng trong hành vi của chương trình, nhưng chỉ cung cấp ở những nơi cần thiết và tất cả điều này đều được thực hiện trong OCaml. Điều này có nghĩa là các mở rộng của OxCaml được thiết kế để làm cho OCaml trở thành một ngôn ngữ xuất sắc cho kỹ thuật hiệu năng. Kỹ thuật hiệu năng đòi hỏi sự kiểm soát, OxCaml hy vọng sự kiểm soát này là an toàn, thuận tiện và có thể dự đoán được. An toàn là một đặc tính quan trọng để nâng cao năng suất của lập trình viên và phát hành mã chính xác. OxCaml được thiết kế để duy trì khả năng suy luận kiểu xuất sắc của OCaml đồng thời tăng thêm tính biểu cảm của hệ thống kiểu. OxCaml hy vọng rằng các mở rộng của nó có thể duy trì và cải thiện một đặc tính của OCaml, đó là làm cho hiệu năng của mã dễ hiểu bằng cách làm rõ các chi tiết hiệu năng quan trọng ở cấp độ kiểu.
Các mở rộng của OxCaml nên là trả tiền theo nhu cầu, tức là người dùng không cần phải chịu thêm sự phức tạp khi không sử dụng khả năng tối ưu hóa bổ sung. Tất cả các chương trình OCaml hợp lệ cũng là các chương trình OxCaml hợp lệ, nhưng mục tiêu sâu xa hơn là làm cho OxCaml có cảm giác như OCaml đã tiến hóa thành một phiên bản tốt hơn, chứ không phải là một ngôn ngữ mới. Để làm được điều này, OxCaml cần tôn trọng các nguyên tắc thiết kế cơ bản của OCaml và duy trì tính an toàn, dễ sử dụng và năng suất của OCaml.
Các mở rộng của OxCaml có thể được chia thành một số lĩnh vực:
- Đồng thời không sợ hãi: Viết các chương trình đồng thời chính xác là rất khó. OxCaml bao gồm các mở rộng của hệ thống kiểu để loại trừ các cuộc đua dữ liệu một cách tĩnh.
- Bố cục: OxCaml cho phép lập trình viên chỉ định bố cục của dữ liệu trong bộ nhớ và cung cấp quyền truy cập gốc vào các mở rộng bộ xử lý SIMD.
- Kiểm soát phân bổ: OxCaml cung cấp các công cụ để kiểm soát phân bổ, giảm áp lực GC, làm cho chương trình hiệu quả hơn về bộ nhớ cache và có tính xác định.
- Chất lượng cuộc sống: OxCaml cũng bao gồm một số mở rộng không đặc biệt nhắm mục tiêu vào lập trình hệ thống, nhưng thấy chúng hữu ích trong công việc hàng ngày, chẳng hạn như tham số đa hình, bao gồm functor, bộ tuple được gắn thẻ và mảng bất biến.
Sử dụng OxCaml: OxCaml là mã nguồn mở và hoan nghênh người dùng thử nghiệm, đặc biệt là các nhà nghiên cứu và những người thích sửa đổi, những người có thể dùng thử hệ thống và cung cấp phản hồi. OxCaml nhấn mạnh tính thử nghiệm vì nó không cam kết về tính ổn định hoặc khả năng tương thích ngược cho các mở rộng của nó (mặc dù nó vẫn duy trì khả năng tương thích ngược với OCaml). OxCaml được thiết kế để dễ sử dụng và vì mục đích này, nó cung cấp một bộ công cụ OCaml tiêu chuẩn đã được sửa đổi, bao gồm quản lý gói tương thích với dune và opam, tích hợp trình chỉnh sửa thông qua LSP-server, định dạng mã nguồn và tạo tài liệu.
Jane Street từ lâu đã mở nguồn nhiều thư viện và công cụ hữu ích. Chúng hiện được phát hành ở hai dạng: một là OCaml thượng nguồn, trong đó các mở rộng của chúng tôi đã bị loại bỏ; và một là OxCaml, trong đó các mở rộng được tận dụng triệt để. Không phải tất cả các mở rộng đều có thể bị xóa, vì vậy một số thư viện sẽ chỉ khả dụng cho OxCaml. Khi các mở rộng cần thiết được tích hợp vào thượng nguồn, chúng tôi sẽ xuất các phiên bản tương thích OCaml của các thư viện này.
Cuối cùng, Jane Street đang tìm kiếm những người thông minh, tốt bụng, những người đam mê khám phá những điều chưa biết và giải quyết các câu đố hóc búa. Trang web cũng cung cấp một liên kết để xem các vị trí đang mở.
HN | Độ nóng: 253 điểm | 73 bình luận | Tác giả: lairv #
https://news.ycombinator.com/item?id=44268782
- OxCaml là một bộ mở rộng của ngôn ngữ lập trình OCaml.
- Nhóm Janet Street không chỉ tạo ra OxCaml mà còn thảo luận về các cân nhắc về hiệu năng khi sử dụng OCaml, đặc biệt trong các tình huống ứng dụng đòi hỏi độ trễ cực thấp.
- Trong giao dịch tần suất cao, việc tạm dừng thu gom rác (GC) có thể trở thành một vấn đề.
- Các hệ thống giao dịch thường không thực hiện cấp phát bộ nhớ sau khi khởi động để tránh tạm dừng GC.
- JavaScript có một thư viện tên là “Zero”, cung cấp một loạt các phương pháp không thực hiện cấp phát bộ nhớ.
- Có người nhầm tưởng “JS” là JavaScript, nhưng thực tế là Jane Street.
- Trong các tình huống giao dịch, có thể tắt GC khi thị trường mở cửa và đóng cửa, và khởi động lại chương trình sau khi đóng cửa.
- Đây là một mẫu thiết kế phổ biến trong các hệ thống ngân hàng, phù hợp với các hệ thống chỉ chạy trong thời gian giao dịch của thị trường.
- Có ý kiến cho rằng, bằng cách tăng đủ RAM, có thể khiến việc không thực hiện GC trong thời gian dài (ví dụ: hơn 6 giờ) trở nên khả thi.
- Có người cho rằng C++ phổ biến hơn bất kỳ ngôn ngữ GC nào (thường là Java, vì OCaml ít phổ biến hơn) trong lĩnh vực tài chính.
- Có người đề cập đến dự án JVM OpenHFT, dự án này được sử dụng trong sản xuất thực tế và cung cấp một góc nhìn bên ngoài để quan sát cơ sở hạ tầng giao dịch tần suất cao.
- Ngôn ngữ Dart hợp nhất tuple và record thành một cấu trúc duy nhất, có thể sử dụng kiểu record trong chú thích kiểu.
Một đế chế adtech đen tối được nuôi dưỡng bởi CAPTCHA giả mạo #
A dark adtech empire fed by fake CAPTCHAs
https://krebsonsecurity.com/2025/06/inside-a-dark-adtech-empire-fed-by-fake-captchas/
Bài viết này phơi bày một đế chế công nghệ quảng cáo đen tối được hỗ trợ bởi Điện Kremlin, đế chế này lợi dụng công nghệ quảng cáo độc hại để vượt qua kiểm duyệt nội dung của các nền tảng truyền thông xã hội, truyền bá thông tin sai lệch. Bài viết mô tả chi tiết sự phức tạp và mối liên hệ lẫn nhau của ngành công nghệ quảng cáo đen tối này.
Bài viết bắt đầu bằng việc đề cập rằng vào tháng 11 năm 2024, các nhà nghiên cứu từ công ty an ninh Qurium đã tiết lộ một mạng lưới thông tin sai lệch có tên là “Doppelganger”, mạng lưới này truyền bá tin tức giả mạo thông qua việc sao chép các trang web, quảng bá các câu chuyện thân Nga và xâm nhập vào giới truyền thông châu Âu. Doppelganger sử dụng dịch vụ “ẩn tên miền” phức tạp, cho phép trang web hiển thị nội dung khác nhau cho các công cụ tìm kiếm và khách truy cập thông thường, từ đó kéo dài thời gian trực tuyến của các trang web thông tin sai lệch và đảm bảo rằng chỉ đối tượng mục tiêu mới có thể nhìn thấy nội dung đã định trước.
Qurium phát hiện ra rằng dịch vụ ẩn tên miền của Doppelganger cũng quảng bá các trang web hẹn hò trực tuyến và chia sẻ một lượng lớn cơ sở hạ tầng với hệ thống phân phối lưu lượng truy cập độc hại (TDS) lâu đời nhất hiện có, VexTrio. VexTrio chủ yếu quản lý lưu lượng truy cập mạng từ các nạn nhân của các vụ lừa đảo trực tuyến, phần mềm độc hại và lừa đảo kỹ thuật xã hội.
Điều tra sâu hơn cho thấy dịch vụ ẩn tên miền của Doppelganger sử dụng nhà cung cấp dịch vụ internet của Thụy Sĩ làm điểm vào đầu tiên của chuỗi chuyển hướng tên miền, và cùng một cơ sở hạ tầng cũng lưu trữ hai dịch vụ tiếp thị liên kết thương hiệu chung, các dịch vụ này chuyển hướng lưu lượng truy cập đến các trang web hẹn hò người lớn đáng ngờ: LosPollos.com và TacoLoco.co.
Mạng quảng cáo LosPollos kết hợp nhiều yếu tố và tham chiếu từ bộ phim truyền hình nổi tiếng “Breaking Bad”, bắt chước chuỗi nhà hàng hư cấu “Los Pollos Hermanos” trong phim, hoạt động như một hoạt động rửa tiền cho những kẻ buôn bán ma túy đá bạo lực. Các thành viên liên kết tham gia LosPollos sẽ nhận được “liên kết thông minh” chứa đầy JavaScript, các liên kết này chuyển hướng lưu lượng truy cập đến VexTrio TDS, sau đó phân phối cho nhiều đối tác quảng cáo khác nhau, bao gồm dịch vụ hẹn hò, ưu đãi rút thăm trúng thưởng, ứng dụng di động lừa đảo, lừa đảo tài chính và trang web tải xuống phần mềm độc hại.
Các thành viên liên kết LosPollos thường nhúng các liên kết thông minh này vào các trang web WordPress bị tấn công thông qua các lỗ hổng đã biết, và mỗi khi người dùng internet rơi vào những cái bẫy này thông qua một trong những trang web bị tấn công của họ, các thành viên liên kết sẽ nhận được một khoản hoa hồng nhỏ.
Bài viết cũng đề cập rằng TacoLoco là một mạng lưới kiếm tiền từ lưu lượng truy cập, sử dụng các thủ đoạn lừa đảo để dụ người dùng internet bật “thông báo đẩy”, một tiêu chuẩn trình duyệt đa nền tảng cho phép các trang web hiển thị tin nhắn bật lên bên ngoài trình duyệt. Các yêu cầu phê duyệt thông báo đẩy của VexTrio và TacoLoco bản thân chúng đã mang tính lừa đảo - ngụy trang thành thử thách “CAPTCHA” để phân biệt giữa lưu lượng truy cập bot tự động và khách truy cập thực. Trong nhiều năm, VexTrio và các đối tác của nó đã dụ dỗ vô số người dùng bật thông báo từ các trang web này, sau đó các thông báo này được sử dụng để liên tục gửi các cảnh báo virus giả mạo và tin nhắn bật lên gây hiểu lầm đến thiết bị của nạn nhân.
Báo cáo thường niên năm 2024 của GoDaddy cho thấy gần 40% các trang web bị xâm nhập vào năm 2024 đã được chuyển hướng đến VexTrio thông qua các liên kết thông minh LosPollos.
Bài viết cũng đề cập đến Adspro Group, một công ty đã đăng ký tại Cộng hòa Séc và Nga, điều hành các dịch vụ LosPollos và TacoLoco, và vận hành cơ sở hạ tầng của mình tại các nhà cung cấp dịch vụ lưu trữ của Thụy Sĩ C41 và Teknology SA. Các trang web LosPollos và TacoLoco tuyên bố rằng nội dung của họ được bảo vệ bản quyền bởi các công ty Thụy Sĩ ByteCore AG và SkyForge Digital AG, hai công ty này được điều hành bởi Giulio Vitorrio Leonardo Cerutti, chủ sở hữu của Teknology SA. Điều tra sâu hơn cho thấy LosPollos và TacoLoco là các ứng dụng được phát triển bởi Holacode, công ty liệt kê Cerutti là CEO của mình.
Các ứng dụng được Holacode tiếp thị bao gồm nhiều dịch vụ VPN, cũng như một ứng dụng có tên Spamshield, tuyên bố có thể chặn các thông báo đẩy không mong muốn. Nhưng Infoblox cho biết vào tháng 1 rằng họ đã thử nghiệm ứng dụng này trên thiết bị di động của riêng mình và phát hiện ra rằng nó ẩn thông báo của người dùng, sau đó ngừng ẩn chúng sau 24 giờ và yêu cầu thanh toán. Spamshield sau đó đã thay đổi tên nhà phát triển của mình từ Holacode thành ApLabz, mặc dù Infoblox chỉ ra rằng các điều khoản dịch vụ của một số ứng dụng ApLabz được đổi thương hiệu vẫn tham chiếu đến Holacode trong các điều khoản dịch vụ của chúng.
Cerutti đã đe dọa kiện tác giả vì tội phỉ báng trước khi bài viết được xuất bản, mặc dù tác giả thậm chí còn chưa đề cập đến tên của anh ta hoặc gửi yêu cầu bình luận cho anh ta. Khi được yêu cầu bình luận về các phát hiện của Qurium và Infoblox, Cerutti kiên quyết phủ nhận bất kỳ mối liên hệ nào với VexTrio. Cerutti khẳng định rằng công ty của anh tuân thủ nghiêm ngặt các quy định của các quốc gia nơi nó hoạt động và họ hoàn toàn minh bạch về tất cả các hoạt động.
Các nhà nghiên cứu từ công ty an ninh Infoblox, hợp tác với Qurium, đã công bố thông tin chi tiết về cơ sở hạ tầng VexTrio cho các đối tác trong ngành của họ. Bốn ngày sau khi Qurium công bố kết quả điều tra của mình, LosPollos đã thông báo tạm ngừng dịch vụ kiếm tiền từ thông báo đẩy của mình. Chưa đầy một tháng sau, Adspro đổi tên thành Aimed Global.
Bài viết kết thúc bằng việc đề cập rằng vào tháng 3 năm 2025, các nhà nghiên cứu của GoDaddy đã ghi nhận DollyWay - một phần mềm độc hại đã chuyển hướng nạn nhân đến VexTrio trong tám năm hoạt động của nó - đột ngột ngừng làm như vậy vào ngày 20 tháng 11 năm 2024. Gần như chỉ sau một đêm, DollyWay và một số dòng phần mềm độc hại khác trước đây sử dụng VexTrio bắt đầu đẩy lưu lượng truy cập của chúng thông qua một TDS khác có tên là Help TDS. Các nhà nghiên cứu đã điều tra sâu hơn các bản ghi DNS lịch sử và t… (Thông tin gốc không được cung cấp đầy đủ ở đây)
HN | Độ nóng: 224 điểm | 114 bình luận | Tác giả: todsacerdoti #
https://news.ycombinator.com/item?id=44263780
- Chức năng thông báo đẩy của trình duyệt đang bị lạm dụng, đặc biệt là các mạng kiếm tiền từ lưu lượng truy cập web lừa người dùng bật thông báo.
- Chức năng thông báo đẩy đã độc hại ngay từ đầu, đặc biệt là cửa sổ bật lên “có bật thông báo hay không”.
- Chức năng thông báo đẩy hữu ích cho các ứng dụng email và trò chuyện dựa trên web, các mục đích sử dụng khác chủ yếu là để giải quyết vấn đề của trang web.
- YouTube sử dụng chức năng thông báo đẩy để người dùng kịp thời nhận được các bản cập nhật video, đây là một tình huống đôi bên cùng có lợi cho người dùng và nền tảng.
- Chức năng thông báo đẩy có thể khiến người dùng bỏ lỡ nội dung, nhưng người dùng có thể chọn không nhấp vào thông báo ngay lập tức.
- Chức năng thông báo đẩy có thể khiến người dùng cảm thấy áp lực, vì chúng tạo ra bầu không khí “tham gia ngay nếu không sẽ bỏ lỡ”.
- Chức năng thông báo đẩy là một phần của Ứng dụng Web lũy tiến (PWA), được sử dụng để trốn tránh việc khóa phần cứng của Apple và Google Store.
- Trình duyệt nên cho phép người dùng chặn Clipboard API để ngăn chặn việc sao chép và dán bị lạm dụng.
- Trong Firefox, bạn có thể tắt một số chức năng thông qua about:config, chẳng hạn như dom.disable_beforeunload và dom.event.clipboardevents.enabled.
- Một số công cụ cộng tác web có thể sử dụng sự kiện beforeunload để đảm bảo dữ liệu được đồng bộ hóa với máy chủ.
- Sự kiện beforeunload có mục đích sử dụng hợp lý trong một số trường hợp, chẳng hạn như trong các công cụ truy cập từ xa để cảnh báo người dùng rằng họ sắp đóng tab.
Show HN: Tôi đã viết một BitTorrent Client từ đầu #
Show HN: I wrote a BitTorrent Client from scratch
https://github.com/piyushgupta53/go-torrent-client
Trang này là bản tóm tắt về trang dự án GitHub có tên “go-torrent-client”. Dưới đây là bản tóm tắt chi tiết bằng tiếng Việt về nội dung chính của trang web:
Tên dự án: go-torrent-client Mô tả dự án: Đây là một ứng dụng khách BitTorrent được triển khai bằng ngôn ngữ Go, hỗ trợ tải xuống tệp bằng giao thức BitTorrent. Dự án này triển khai các chức năng cốt lõi của ứng dụng khách BitTorrent, bao gồm phân tích tệp torrent, khám phá peer và tải xuống tệp.
Đặc điểm:
- Mã hóa/giải mã Bencode: Hỗ trợ tất cả các kiểu Bencode (chuỗi, số nguyên, danh sách, từ điển), đồng thời có khả năng xử lý và xác thực lỗi mạnh mẽ.
- Xử lý tệp Torrent: Phân tích cú pháp tệp .torrent (bao gồm torrent một tệp và nhiều tệp), tính toán hàm băm thông tin, trích xuất hàm băm khối và hỗ trợ tất cả các trường tệp torrent tiêu chuẩn.
- Khám phá và giao tiếp Peer: Hỗ trợ trình theo dõi HTTP, giao thức bắt tay peer và giao thức tin nhắn BitTorrent hoàn chỉnh, cũng như quản lý kết nối peer.
- Chức năng tải xuống: Quản lý khối và mảnh, hỗ trợ tải xuống đồng thời, theo dõi tiến trình và lắp ráp tệp cho torrent một tệp và nhiều tệp, với quản lý lưu trữ chi tiết ở cấp độ khối.
Cấu trúc dự án:
- cmd/: Giao diện dòng lệnh và ứng dụng chính.
- internal/: Các gói nội bộ, bao gồm mã hóa/giải mã bencode, xử lý tệp torrent, triển khai giao thức tracker, giao tiếp peer và quản lý tải xuống.
- pkg/: Các gói công khai.
Yêu cầu: Cần Go 1.21 trở lên.
Cài đặt:
- Sử dụng git để sao chép dự án: git clone https://github.com/yourusername/go-torrent.git
- Vào thư mục dự án: cd go-torrent
- Tải xuống các dependency: go mod download
Hướng dẫn sử dụng: Hướng dẫn sử dụng sẽ được thêm vào khi dự án phát triển.
Trạng thái phát triển: Dự án đang được phát triển tích cực. Trạng thái triển khai hiện tại có thể được tìm thấy trong tệp checkpoint.md.
Tính năng dự kiến: Bao gồm hỗ trợ liên kết từ tính (magnet link), giao thức trao đổi siêu dữ liệu và hỗ trợ DHT (Bảng băm phân tán).
Lời cảm ơn: Cung cấp các liên kết đến đặc tả giao thức BitTorrent và đặc tả Bencode.
Giới thiệu: Đây là một ứng dụng khách BitTorrent được triển khai bằng ngôn ngữ Go.
Tài nguyên: Cung cấp tệp README và thông tin về giấy phép MIT.
Hoạt động: Dự án đã nhận được 218 sao, 2 người theo dõi và 8 nhánh.
Bản tóm tắt trên bao gồm các thông tin chính trên trang web, bao gồm giới thiệu dự án, đặc điểm, cấu trúc dự án, hướng dẫn cài đặt và sử dụng, trạng thái phát triển, các tính năng dự kiến và lời cảm ơn.
HN | Độ nóng: 185 điểm | 44 bình luận | Tác giả: piyushgupta53 #
https://news.ycombinator.com/item?id=44265851
- Khen ngợi công việc của nhà phát triển khi viết một ứng dụng khách BitTorrent từ đầu và cho rằng đây là một cách hay để thử thách bản thân
- Đề xuất nhà phát triển giới hạn kích thước phân bổ động trong bộ giải mã bencode để ngăn chặn các đầu vào độc hại gây ra tấn công DoS
- Đề xuất sử dụng Kaitai Struct để viết bộ giải mã bencode để tránh một số vấn đề phổ biến
- Đề xuất thêm hướng dẫn sử dụng đơn giản vào README để người dùng biết cách tải xuống tệp .torrent
- Đề xuất thêm hỗ trợ cho liên kết magnet và cho rằng đây là một tính năng được lên kế hoạch
- Hỏi tại sao lại sử dụng phiên bản Go cũ hơn 1.21, có lý do đặc biệt nào không
- Đề cập rằng hỗ trợ Windows 7 có thể là một trong những lý do sử dụng phiên bản Go cũ
- Cho rằng hỗ trợ nhiều nền tảng hơn là điều tốt, ngay cả các phiên bản Windows cũ
- Nhớ lại đã thực hiện một dự án tương tự khi còn học đại học, cho rằng loại dự án này là một cách hay để học ngôn ngữ mới
- Hỏi liệu có hỗ trợ liên kết magnet hay không, được biết đây là một tính năng được lên kế hoạch
- Hỏi về độ khó khi thêm GUI và đề cập rằng trước đây không thấy nhiều triển khai GUI của Go
- Cung cấp một số liên kết tài nguyên về các dự án GUI của Go và chia sẻ quan điểm cá nhân về các thư viện GUI khác nhau
- Hỏi về tính đầy đủ của dự án, liệu nó có xử lý các vấn đề phức tạp như DHT, Magnet và NAT traversal hay không
- Cho rằng liên kết magnet tương đối đơn giản, nhưng DHT là một lĩnh vực phức tạp và không phải tất cả các ứng dụng khách đều hỗ trợ DHT
- Hỏi liệu có hỗ trợ v2 và mutable torrents hay không
- Chỉ ra rằng dự án thiếu các vấn đề như khôi phục sau sự cố, bắt tay mã hóa ngang hàng hoặc hỗ trợ uTP cơ bản, cũng như xử lý NAT và bảo vệ bộ nhớ, cho rằng đây là những điều kiện cần thiết trong môi trường sản xuất
- Hỏi liệu có thể sử dụng dự án này làm thư viện hay không và hy vọng nó có thể được mô-đun hóa
- Một số người nghi ngờ rằng các bình luận có vẻ như được tạo ra bởi máy và bày tỏ sự nghi ngờ về tính xác thực của bài đăng