2025-07-11 Top Stories #
- Nghiên cứu phát hiện công cụ AI lại dẫn đến việc giảm năng suất của các nhà phát triển mã nguồn mở giàu kinh nghiệm.
- Grok 4 được phát hành với tư cách là mô hình AI mạnh nhất toàn cầu, gây ra các cuộc thảo luận rộng rãi về giá cả và chức năng của nó.
- Tòa án Đức phán quyết công nghệ theo dõi của Meta vi phạm các quy định về quyền riêng tư của Châu Âu, yêu cầu bồi thường và có thể ảnh hưởng đến các vụ kiện tập thể trong tương lai.
- Dự án mã nguồn mở FlopperZiro cung cấp một thiết bị nhân bản Flipper Zero chi phí thấp, để DIY và học tập.
- Giao thức MCP-B cho phép AI tương tác trực tiếp với các chức năng của trình duyệt, thông qua API để đạt được tự động hóa hiệu quả.
- Hoạt động giao tiếp xã hội của giới trẻ Mỹ giảm, đặc biệt là thời gian dự tiệc, phản ánh những thay đổi trong cơ cấu xã hội và kinh tế.
- Gemini 2.5 thể hiện xuất sắc trong nhiệm vụ phát hiện hộp giới hạn, nhưng vẫn cần tối ưu hóa để nâng cao độ chính xác.
- Nghiên cứu loại hình học về tiếng Anh Canada tiết lộ từ vựng và cách sử dụng độc đáo của nó, được phân loại thành sáu loại.
- Thư viện công cộng ở Virginia đã chống lại thành công việc tiếp quản vốn cổ phần tư nhân, làm dấy lên cuộc thảo luận về sự cân bằng giữa dịch vụ công và lợi nhuận.
- Dự án máy chủ MCP đơn giản hóa quá trình tìm kiếm và tải xuống tài liệu từ Anna’s Archive, nâng cao trải nghiệm người dùng.
Đo lường tác động của AI lên năng suất của các nhà phát triển mã nguồn mở giàu kinh nghiệm #
Measuring the impact of AI on experienced open-source developer productivity
https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
Trang web này là một bài viết về nghiên cứu ảnh hưởng của trí tuệ nhân tạo (AI) đến năng suất của các nhà phát triển mã nguồn mở giàu kinh nghiệm vào đầu năm 2025.
Bối cảnh nghiên cứu: Bài viết bắt đầu bằng việc chỉ ra rằng, mặc dù các bài kiểm tra chuẩn về mã hóa/tác nhân rất hữu ích để hiểu khả năng của AI, nhưng những bài kiểm tra này thường hy sinh tính thực tế để đổi lấy quy mô và hiệu quả. Các nhiệm vụ này khép kín, không yêu cầu ngữ cảnh trước đó để hiểu và được đánh giá bằng thuật toán, điều này không nắm bắt được nhiều khả năng quan trọng. Những đặc điểm này có thể dẫn đến việc các bài kiểm tra chuẩn đánh giá quá cao khả năng của AI. Mặt khác, vì các bài kiểm tra chuẩn không có tương tác trực tiếp với con người, nên mô hình có thể không hoàn thành nhiệm vụ, mặc dù đã đạt được những tiến bộ đáng kể, vì một số nút thắt cổ chai nhỏ mà con người sẽ sửa chữa trong quá trình sử dụng thực tế. Điều này có thể dẫn đến việc chúng ta đánh giá thấp khả năng của mô hình. Nói chung, rất khó để chuyển đổi trực tiếp điểm số của bài kiểm tra chuẩn thành tác động thực tế.
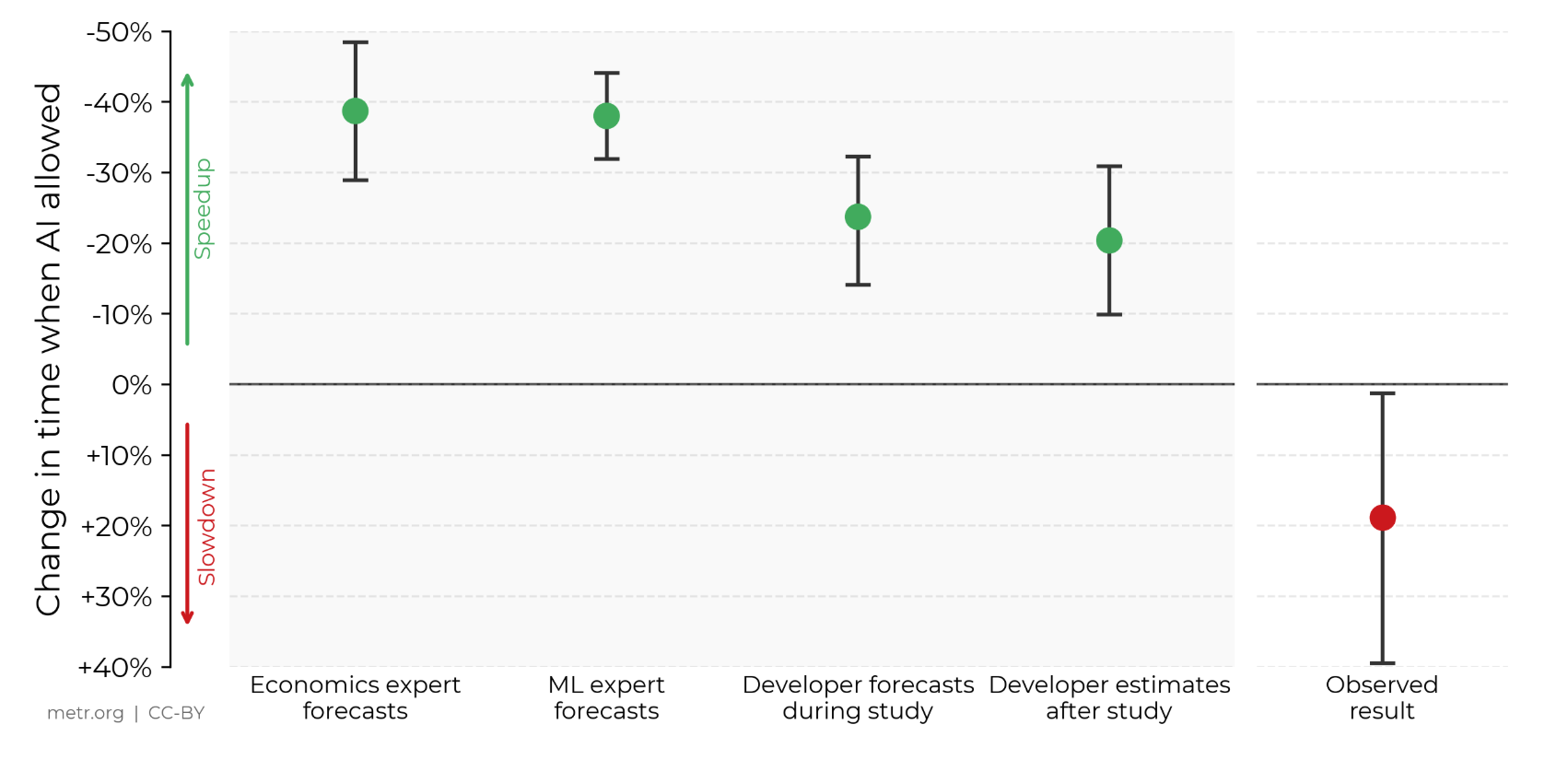 Động cơ nghiên cứu: Bài viết đề cập rằng, việc đánh giá tác động của AI trong thế giới thực là rất quan trọng để hiểu rõ hơn về tác động của AI đối với chính việc nghiên cứu và phát triển AI (R&D), điều này có thể mang lại những rủi ro đáng kể. Ví dụ, sự tiến bộ cực kỳ nhanh chóng của AI có thể dẫn đến sự sụp đổ của việc giám sát hoặc các biện pháp bảo đảm. Đo lường tác động của AI đối với năng suất của các nhà phát triển phần mềm cung cấp bằng chứng bổ sung cho tác động tổng thể của AI đối với việc tăng tốc R&D AI.
Phương pháp nghiên cứu: Để đo lường trực tiếp tác động thực tế của các công cụ AI đối với việc phát triển phần mềm, các nhà nghiên cứu đã tuyển dụng 16 nhà phát triển giàu kinh nghiệm, đến từ các kho mã nguồn mở lớn (trung bình 22k+ sao và 1M+ dòng mã) và đã đóng góp cho các kho này trong nhiều năm. Các nhà phát triển đã cung cấp danh sách 246 vấn đề thực tế, có giá trị đối với các kho mã - bao gồm sửa lỗi, thêm tính năng và tái cấu trúc trong công việc thông thường. Sau đó, những vấn đề này được phân công ngẫu nhiên, cho phép hoặc không cho phép sử dụng AI khi giải quyết chúng. Khi được phép sử dụng AI, các nhà phát triển có thể chọn sử dụng bất kỳ công cụ nào (chủ yếu là Cursor Pro với Claude 3.5/3.7 Sonnet - mô hình tiên tiến tại thời điểm nghiên cứu); khi không được phép sử dụng, họ làm việc mà không có sự trợ giúp của AI tạo sinh. Các nhà phát triển hoàn thành các nhiệm vụ này trong khi ghi lại màn hình (trung bình hai giờ cho mỗi nhiệm vụ), sau đó tự báo cáo tổng thời gian thực hiện mà họ cần. Các nhà nghiên cứu trả cho các nhà phát triển mức thù lao 150 đô la mỗi giờ cho sự tham gia của họ.
Kết quả cốt lõi: Khi các nhà phát triển được phép sử dụng các công cụ AI, họ mất nhiều hơn 19% thời gian để hoàn thành nhiệm vụ so với khi không được phép sử dụng - đây là một sự chậm lại đáng kể, trái ngược với niềm tin của các nhà phát triển và dự đoán của các chuyên gia. Khoảng cách giữa nhận thức và thực tế này là đáng kinh ngạc: các nhà phát triển dự kiến AI sẽ giúp họ tăng tốc độ lên 24%, ngay cả sau khi trải qua sự chậm lại, họ vẫn tin rằng AI đã giúp họ tăng tốc độ lên 20%.
Thảo luận: Bài viết thảo luận về cách điều hòa kết quả nghiên cứu với thành tích xuất sắc của các bài kiểm tra chuẩn AI và các báo cáo rộng rãi về tính hữu ích và việc áp dụng rộng rãi các công cụ AI. Những nguồn bằng chứng này đưa ra những câu trả lời mâu thuẫn một phần về việc các tác nhân AI hoàn thành nhiệm vụ hoặc tăng tốc khả năng của con người. Bài viết tóm tắt những nguồn bằng chứng này và chỉ ra rằng đây không phải là toàn diện, mà chỉ ra một cách khái quát một số điểm khác biệt quan trọng.
Phân tích yếu tố: Các nhà nghiên cứu đã điều tra 20 yếu tố tiềm năng có thể giải thích sự chậm lại và phát hiện ra 5 yếu tố có thể đóng góp vào điều này. Họ đã loại trừ nhiều hiện vật thử nghiệm - các nhà phát triển đã sử dụng các mô hình tiên tiến, tuân thủ việc phân công xử lý của họ, không bỏ cuộc một cách khác biệt đối với các vấn đề (ví dụ: bỏ cuộc đối với các vấn đề bị cấm AI khó xử lý, làm giảm độ khó trung bình của AI bị cấm) và gửi các PR có chất lượng tương đương, bất kể có sử dụng AI hay không. Sự chậm lại vẫn tiếp diễn trong các phép đo kết quả khác nhau, phương pháp ước tính và nhiều tập hợp con/phân tích dữ liệu khác. Để biết thêm chi tiết và phân tích, vui lòng tham khảo bài viết.
Động cơ nghiên cứu: Bài viết đề cập rằng, việc đánh giá tác động của AI trong thế giới thực là rất quan trọng để hiểu rõ hơn về tác động của AI đối với chính việc nghiên cứu và phát triển AI (R&D), điều này có thể mang lại những rủi ro đáng kể. Ví dụ, sự tiến bộ cực kỳ nhanh chóng của AI có thể dẫn đến sự sụp đổ của việc giám sát hoặc các biện pháp bảo đảm. Đo lường tác động của AI đối với năng suất của các nhà phát triển phần mềm cung cấp bằng chứng bổ sung cho tác động tổng thể của AI đối với việc tăng tốc R&D AI.
Phương pháp nghiên cứu: Để đo lường trực tiếp tác động thực tế của các công cụ AI đối với việc phát triển phần mềm, các nhà nghiên cứu đã tuyển dụng 16 nhà phát triển giàu kinh nghiệm, đến từ các kho mã nguồn mở lớn (trung bình 22k+ sao và 1M+ dòng mã) và đã đóng góp cho các kho này trong nhiều năm. Các nhà phát triển đã cung cấp danh sách 246 vấn đề thực tế, có giá trị đối với các kho mã - bao gồm sửa lỗi, thêm tính năng và tái cấu trúc trong công việc thông thường. Sau đó, những vấn đề này được phân công ngẫu nhiên, cho phép hoặc không cho phép sử dụng AI khi giải quyết chúng. Khi được phép sử dụng AI, các nhà phát triển có thể chọn sử dụng bất kỳ công cụ nào (chủ yếu là Cursor Pro với Claude 3.5/3.7 Sonnet - mô hình tiên tiến tại thời điểm nghiên cứu); khi không được phép sử dụng, họ làm việc mà không có sự trợ giúp của AI tạo sinh. Các nhà phát triển hoàn thành các nhiệm vụ này trong khi ghi lại màn hình (trung bình hai giờ cho mỗi nhiệm vụ), sau đó tự báo cáo tổng thời gian thực hiện mà họ cần. Các nhà nghiên cứu trả cho các nhà phát triển mức thù lao 150 đô la mỗi giờ cho sự tham gia của họ.
Kết quả cốt lõi: Khi các nhà phát triển được phép sử dụng các công cụ AI, họ mất nhiều hơn 19% thời gian để hoàn thành nhiệm vụ so với khi không được phép sử dụng - đây là một sự chậm lại đáng kể, trái ngược với niềm tin của các nhà phát triển và dự đoán của các chuyên gia. Khoảng cách giữa nhận thức và thực tế này là đáng kinh ngạc: các nhà phát triển dự kiến AI sẽ giúp họ tăng tốc độ lên 24%, ngay cả sau khi trải qua sự chậm lại, họ vẫn tin rằng AI đã giúp họ tăng tốc độ lên 20%.
Thảo luận: Bài viết thảo luận về cách điều hòa kết quả nghiên cứu với thành tích xuất sắc của các bài kiểm tra chuẩn AI và các báo cáo rộng rãi về tính hữu ích và việc áp dụng rộng rãi các công cụ AI. Những nguồn bằng chứng này đưa ra những câu trả lời mâu thuẫn một phần về việc các tác nhân AI hoàn thành nhiệm vụ hoặc tăng tốc khả năng của con người. Bài viết tóm tắt những nguồn bằng chứng này và chỉ ra rằng đây không phải là toàn diện, mà chỉ ra một cách khái quát một số điểm khác biệt quan trọng.
Phân tích yếu tố: Các nhà nghiên cứu đã điều tra 20 yếu tố tiềm năng có thể giải thích sự chậm lại và phát hiện ra 5 yếu tố có thể đóng góp vào điều này. Họ đã loại trừ nhiều hiện vật thử nghiệm - các nhà phát triển đã sử dụng các mô hình tiên tiến, tuân thủ việc phân công xử lý của họ, không bỏ cuộc một cách khác biệt đối với các vấn đề (ví dụ: bỏ cuộc đối với các vấn đề bị cấm AI khó xử lý, làm giảm độ khó trung bình của AI bị cấm) và gửi các PR có chất lượng tương đương, bất kể có sử dụng AI hay không. Sự chậm lại vẫn tiếp diễn trong các phép đo kết quả khác nhau, phương pháp ước tính và nhiều tập hợp con/phân tích dữ liệu khác. Để biết thêm chi tiết và phân tích, vui lòng tham khảo bài viết.
Bài viết này cung cấp một nghiên cứu thực nghiệm về tác động thực tế của các công cụ AI trong lĩnh vực phát triển phần mềm vào đầu năm 2025, tiết lộ những hạn chế của các công cụ AI trong việc cải thiện năng suất của nhà phát triển và khám phá sự khác biệt giữa những phát hiện này với các bài kiểm tra chuẩn AI và ứng dụng thực tế.
HN | Độ nóng: 483 điểm | 306 bình luận | Tác giả: dheerajvs #
https://news.ycombinator.com/item?id=44522772
- Bài báo này cho thấy rằng việc sử dụng các công cụ AI có thể có một đường cong học tập rất cao, dẫn đến việc các nhà phát triển giảm năng suất trong quá trình thích ứng.
- Có ý kiến cho rằng, đối với LLMs (mô hình ngôn ngữ lớn), việc đổ lỗi cho người dùng là một sự trốn tránh, các sản phẩm công nghệ khác không làm như vậy.
- Các nhà phát triển cho rằng, các công cụ kỹ thuật thường cần kinh nghiệm để sử dụng hiệu quả, các công cụ AI cũng không ngoại lệ.
- Nghiên cứu chỉ ra rằng, ngay cả khi nhà phát triển có kinh nghiệm về AI, họ cũng có thể thể hiện kém hơn khi sử dụng AI, điều này có thể làm tăng tốc độ tương đối của AI.
- Kết quả nghiên cứu cho thấy, các nhà phát triển tự đánh giá quá lạc quan sau khi sử dụng AI, năng suất thực tế có thể thấp hơn dự kiến.
- Có ý kiến cho rằng, việc nâng cao kỹ năng AI có thể đến từ việc giảm thời gian chờ đợi và thời gian nhàn rỗi trong quy trình làm việc.
- Dữ liệu nghiên cứu cho thấy, khi các nhà phát triển sử dụng AI, thời gian mã hóa, kiểm tra và nghiên cứu chủ động giảm, trong khi thời gian nhàn rỗi và thời gian tương tác với AI tăng lên.
- Có người chỉ ra rằng, việc phân tích thời gian thành thời gian tuyệt đối (giờ) có thể hữu ích hơn so với tỷ lệ phần trăm, vì số giờ thực tế có thể làm tăng tỷ lệ thời gian cho các nhiệm vụ liên quan đến AI.
Ra mắt Grok 4 [video] # #
Grok 4 Launch [video] #
https://twitter.com/xai/status/1943158495588815072
Giới thiệu Grok 4, mô hình AI mạnh mẽ nhất thế giới Nội dung chính:
- Phát hành Grok 4: Trang web thông báo về việc phát hành Grok 4, được mô tả là mô hình AI mạnh mẽ nhất thế giới. Trang web có một liên kết phát trực tiếp, người dùng có thể nhấp vào để xem buổi trình diễn trực tiếp của Grok 4.
- Thông tin phát trực tiếp: Thời gian phát trực tiếp là 12:01 PM ngày 10 tháng 7 và đã thu hút 20,6 triệu lượt xem. Buổi phát trực tiếp đã nhận được 4,3 nghìn lượt trả lời, 8,2 nghìn lượt thích và 26 nghìn lượt chia sẻ, cũng như 7,8 nghìn bình luận.
- Tương tác người dùng: Trang web khuyến khích người dùng mới đăng ký để nhận được dòng thời gian được cá nhân hóa. Người dùng có thể đăng ký bằng tài khoản Apple hoặc tạo tài khoản mới. Trong quá trình đăng ký, người dùng cần đồng ý với các điều khoản dịch vụ và chính sách bảo mật, bao gồm cả việc sử dụng Cookie.
- Gợi ý về vấn đề kỹ thuật: Nếu gặp sự cố trong quá trình đăng ký, trang web khuyên người dùng nên thử tải lại trang.
- Tuyên bố pháp lý: Cuối trang web cung cấp các liên kết đến điều khoản dịch vụ, chính sách bảo mật và chính sách Cookie, cũng như thông tin bản quyền, cho biết bản quyền thuộc về X Corp.
HN | Độ nóng: 419 điểm | 544 bình luận | Tác giả: meetpateltech #
https://news.ycombinator.com/item?id=44517055
- Mô hình “hạng nặng” của Grok 4 có giá 300 đô la mỗi tháng, giá dường như đang tăng lên, trong khi chúng ta đã được hứa rằng giá sẽ giảm.
- Có người cho rằng nhiều công ty có thể không có đủ GPU, đây là vấn đề mà Google có thể không gặp phải.
- Có thể sử dụng Gemini 2.5 Pro miễn phí trong AI Studio và có thể thiết lập ngân sách suy nghĩ lên đến 32k mà không cần phải trả bất kỳ chi phí nào.
- Có người cho rằng giá giảm là của các sản phẩm cấp thấp và giá của cùng một hiệu suất theo thời gian, trong khi phạm vi giá trở nên rộng hơn là một dấu hiệu của sự trưởng thành.
- Có người cho rằng LLMs (mô hình ngôn ngữ lớn) có khuynh hướng tự do, và một dự án LLM bảo thủ có thể rất thú vị.
- Có người cho rằng trí thông minh của LLMs không có nghĩa là trí thông minh đạo đức, chúng có thể vừa có năng lực vừa khó chịu.
- Có người cho rằng tiêu chuẩn về trình độ viết được đặt quá cao, vì trong lịch sử có rất ít người có thể viết tốt.
- Có người cho rằng LLMs có thể có thành kiến với Đảng Dân chủ Hoa Kỳ, trong khi những người theo Đảng Cộng hòa Hoa Kỳ quá cực đoan để có thể được gọi là “bảo thủ”.
Tòa án Đức phán quyết công nghệ theo dõi của Meta vi phạm luật riêng tư châu Âu #
German court rules Meta tracking technology violates European privacy laws
https://therecord.media/german-court-meta-tracking-tech
Tòa án Đức phán quyết công nghệ theo dõi của Meta vi phạm các quy định về quyền riêng tư của Châu Âu
Một tòa án ở Đức gần đây đã ra phán quyết yêu cầu Meta bồi thường 5.000 euro (khoảng 5.900 đô la Mỹ) cho một người dùng Facebook ở Đức, người đã kiện nền tảng Meta vì nhúng công nghệ theo dõi vào các trang web của bên thứ ba. Phán quyết này có thể mở đường cho các khoản tiền phạt lớn trong tương lai do vi phạm quyền riêng tư dữ liệu, đặc biệt là các vấn đề liên quan đến pixel và các công cụ tương tự.

Tòa án khu vực Leipzig của Đức đã phán quyết vào thứ Sáu tuần trước rằng pixel theo dõi và bộ công cụ phát triển phần mềm (SDK) của Meta được nhúng vào vô số trang web và ứng dụng, các công nghệ này thu thập dữ liệu người dùng mà không có sự đồng ý của họ, vi phạm Quy định chung về bảo vệ dữ liệu (GDPR) của Châu Âu.
Phán quyết của tòa án ủng hộ nguyên đơn đã tạo ra một tiền lệ cho phép những người dùng khác khởi kiện mà không cần “chứng minh rõ ràng thiệt hại cá nhân”, theo thông cáo báo chí của Tòa án khu vực Leipzig. Thông cáo báo chí đề cập: “Miễn là người dùng truy cập trang web của bên thứ ba hoặc sử dụng ứng dụng, Meta có thể nhận dạng riêng từng người dùng bất kỳ lúc nào, ngay cả khi họ không đăng nhập thông qua tài khoản Instagram và Facebook.”
Thông cáo báo chí cũng chỉ ra rằng Meta “vô cùng vi phạm” luật bảo vệ dữ liệu của Châu Âu bằng cách xử lý dữ liệu cá nhân để “xây dựng hồ sơ” người dùng Facebook, hành vi này mang lại hàng tỷ lợi nhuận cho gã khổng lồ công nghệ này.
Các chuyên gia cho biết phán quyết này khiến tất cả các trang web và ứng dụng sử dụng công nghệ theo dõi có nguy cơ phải đối mặt với các vụ kiện lớn. Ronni K. Gothard Christiansen, Giám đốc điều hành của AesirX, cho biết phán quyết này tạo ra một tiền lệ cho các vụ kiện tập thể, có “tiềm năng phá vỡ hoạt động kinh doanh”. AesirX là một công ty tư vấn giúp các doanh nghiệp tuân thủ các quy định về quyền riêng tư dữ liệu. Christiansen cho biết, những vụ kiện như vậy có thể bao gồm tất cả khách truy cập từ Đức đã sử dụng Meta pixel hoặc các công nghệ theo dõi khác mà không có sự đồng ý của người dùng. Ông nói thêm: “Nếu số lượng khách truy cập lên đến hàng chục nghìn hoặc thậm chí hàng triệu, khoản bồi thường 5.000 euro sẽ nhanh chóng tích lũy.”
HN | Độ nóng: 348 điểm | 161 bình luận | Tác giả: bundie #
https://news.ycombinator.com/item?id=44517424
- Mặc dù phán quyết của tòa án Đức rất đáng chú ý, nhưng tác động thực tế có thể bị hạn chế, vì cơ chế kiện tập thể ở châu Âu khác với Hoa Kỳ, và người tiêu dùng Đức khó có khả năng khởi kiện cá nhân vì pixel theo dõi.
- Người tiêu dùng Đức mặc định bị thêm vào theo dõi, khác với các nước châu Âu khác, đây cũng là lý do có các vụ kiện tập thể chống lại X và TikTok.
- Có người đề xuất có thể thương mại hóa việc này, thông qua ký hợp đồng để nhận bồi thường 2500 euro.
- Có người đề cập rằng mô hình kinh doanh này đã tồn tại trong hợp đồng thuê nhà.
- Có người đề cập rằng, đối với vé máy bay bị hủy hoặc trì hoãn, có một số trang web có thể giúp người dùng nhận bồi thường.
- Ở Thụy Điển đã xuất hiện một số doanh nghiệp, thông qua các công ty luật thu thập tiền thuê nhà trả quá.
- Có người chỉ ra rằng, phán quyết này có thể không đứng vững trong kháng cáo, vì quyết định đầy đủ của tòa án vẫn chưa được công bố.
- Có người không hiểu sự phân chia trách nhiệm giữa Facebook và nhà điều hành trang web, cho rằng theo GDPR, trang web phải chịu trách nhiệm có được sự đồng ý của người dùng trước khi chuyển dữ liệu cho mạng quảng cáo.
- Theo quyết định của tòa án, các trang web và ứng dụng sử dụng công nghệ theo dõi có thể phải đối mặt với các vụ kiện lớn.
- Có người đặt câu hỏi về ý nghĩa của trang web như một “địa điểm”, cho rằng GDPR không đề cập rõ ràng đến việc theo dõi.
- Có người đề xuất rằng, ngay cả khi trang web có được sự đồng ý của người dùng để nhúng công nghệ Facebook, khả năng Facebook xác định người dùng cá nhân có thể vẫn không tuân thủ quy định GDPR.
- Có người đề xuất rằng, có thể có một số công ty luật đại diện cho những người dùng trong cùng tình huống khởi kiện và thu một tỷ lệ phần trăm nhất định.
- Có người đề cập rằng, châu Âu không có hệ thống kiện tập thể giống hệt như Hoa Kỳ, nhưng có chỉ thị của EU cho phép “hành động đại diện”, phạm vi của nó hẹp hơn.
- Có người đề cập rằng, có các văn phòng luật sư có thể xử lý các trường hợp cá nhân như vậy, nếu trường hợp kinh doanh đủ lớn.
- Có người đề cập rằng, có thể trực tiếp nhập dữ liệu vào biểu mẫu do hãng hàng không cung cấp để nhận bồi thường.
Show HN: FlopperZiro – Một bản sao Flipper Zero mã nguồn mở tự làm #
Show HN: FlopperZiro – A DIY open-source Flipper Zero clone
https://github.com/lraton/FlopperZiro
Flopper Ziro là một dự án nhân bản Flipper Zero dựa trên Arduino IDE, nhằm mục đích cung cấp một thiết bị giá rẻ, DIY và hoàn toàn mã nguồn mở. Dự án này được tạo bởi lraton, mặc dù nó chỉ là một dự án thú vị, không chuyên nghiệp và không có ý định thay thế các thiết bị chuyên nghiệp.
Thông tin chính của dự án: #
- Tên dự án: Flopper Ziro
- Tác giả: lraton
- Nền tảng: GitHub
- Trạng thái dự án: Đang trong quá trình phát triển, các chức năng chưa hoàn thiện
Các thành phần chính: #
- STM32-L432KC (Vi điều khiển)
- FS1000a (Bộ phát RF)
- RXB12 (Bộ thu RF)
- PN532 (Mô-đun RFID/NFC)
- PN7150 (Đang thử nghiệm)
- LED hồng ngoại và bộ thu - 2N222A PBFREE (Transistor)
- SSD1306 (Màn hình OLED 128x64)
- Mở rộng lưu trữ thẻ TF - TP4056 (Bộ sạc pin)
- Mô-đun tăng áp DC-DC 5V
- Nhiều nút bấm (6x6x8mm)
- Cổng Micro USB
- Pin lithium 3.7V
Chức năng chính: #
- RubberDucky: Thiết bị USB có thể lập trình
- RFID/NFC: Chức năng đang được phát triển
- Chức năng hồng ngoại: Có thể đọc tín hiệu hồng ngoại và mô phỏng hoặc lưu
- Chức năng RF: Có thể đọc tín hiệu RF và mô phỏng hoặc lưu
- Lưu trữ thẻ SD: Hỗ trợ lưu và tải dữ liệu từ thẻ SD
- Hiển thị phần trăm pin
- Hiển thị phần trăm dung lượng lưu trữ thẻ SD còn lại
- Lập trình thông qua Arduino IDE
- Vỏ in 3D: Dự kiến sản xuất (Liên kết vỏ)
Việc cần làm: #
Hãy cung cấp văn bản tiếng Trung Giản thể mà bạn muốn tôi dịch. Tôi sẽ dịch nó sang tiếng Việt theo đúng yêu cầu của bạn.
- Giải quyết vấn đề giữa SSD1306 và thẻ SD
- Hoàn thành menu SD
- Triển khai chức năng lưu / tải
- Tạo danh sách SD
- Sửa lỗi trong danh sách SD
- Hoàn thành chức năng quét và gửi tần số vô tuyến
- Sửa lỗi hiển thị dữ liệu hồng ngoại
- Hoàn thành chức năng RFID: Đọc UID, đọc ISO14443B, mô phỏng, lưu dữ liệu RFID
- Làm PCB đầu tiên
- Thiết kế PCB phiên bản mới
- Thử sử dụng PN7150 thay thế PN532
- Viết tài liệu liên quan
Lưu ý: #
Mục tiêu của dự án này là để giải trí và học tập, không nên được coi là sự thay thế cho các thiết bị chuyên nghiệp.
HN | Độ nóng: 343 điểm | 73 bình luận | Tác giả: iraton #
https://news.ycombinator.com/item?id=44512763
- LilyGo T-Embed CC1100 có khả năng phần cứng tương tự Flipper Zero, giá thấp hơn, chạy firmware Bruce Pentest, nhưng không hoàn thiện bằng Flipper Zero.
- Sự phổ biến của nhiều thiết bị như Arduino và Raspberry Pi không phải vì khả năng phần cứng, mà là vì sự tồn tại của “cộng đồng quy mô”.
- Cộng đồng Flipper Zero tương đối nhỏ, phát triển không sôi động bằng cộng đồng Arduino và ESP32.
- Nhiều hướng dẫn “Cách làm X trên Raspberry Pi” thực chất là “Cách làm X trên Linux”, nhưng được chú ý vì liên kết với bo mạch phổ biến.
- Các hướng dẫn và công cụ do cộng đồng tạo ra có thể rộng hơn so với một thiết bị phổ biến cụ thể, dù là cố ý hay ngẫu nhiên.
- Mọi người bắt đầu từ những điểm khác nhau, cộng đồng Raspberry Pi đã làm tốt trong việc giảm rào cản thông tin đầu vào.
- Việc phát minh lại bánh xe giúp hiểu rõ hơn về nó.
- Bản thân tên dự án đã đáng để cười.
- Dự án này do người Ý khởi xướng, tiếng Anh có thể không phải là ngôn ngữ đầu tiên của họ, không nên đánh giá tiêu cực vì vấn đề ngôn ngữ.
- Thiết bị Kiisu có chức năng 1:1 với Flipper Zero và có các chức năng bổ sung.
- Dự án này và Capibara Zero vẫn còn khoảng cách so với Flipper Zero về hỗ trợ phần mềm, Flipper Zero có sự hỗ trợ mạnh mẽ từ cộng đồng.
- So với Raspberry Pi, các máy tính bảng đơn khác có thể rẻ hơn, nhưng phần mềm thường kém hơn và không có sự hỗ trợ của cộng đồng lớn.
- Nếu bạn kiên trì sử dụng các sản phẩm RockChip, phần mềm không tệ.
- Miễn là chúng có kernel Linux, thì không cho rằng phần mềm kém hơn Raspberry Pi.
- Nhiều bản cập nhật phần mềm thiết bị bị giới hạn bởi kernel, khó cập nhật.
- Theo nhu cầu cá nhân, định nghĩa về “tốt hơn” là khác nhau.
- Thư viện firmware của Flipper Zero đã được lưu trữ vào ngày 12 tháng 4 năm 2025, khó có khả năng hồi sinh hoặc có tính cạnh tranh.
- Trong thời gian diễn ra Defcon, các khách sạn ở Las Vegas có thể có quan điểm về các thiết bị như vậy.
- Từ góc độ của quản trị viên, các thiết bị như vậy không lý tưởng tại các hội nghị thân thiện với hacker, nhưng từ góc độ vận hành, có thể đổ lỗi cho Kevin Mitnick.
- Dự án Kiisu có thể chạy mã Flipper và mã Flipper đã sửa đổi.
- Dự án này chủ yếu là một công cụ tấn công replay 433 MHz, có thể chỉ tạo ra dữ liệu tùy ý được điều chế OOK.
- Dự án này chỉ là một dự án thú vị, không chuyên nghiệp và không phải là sự thay thế cho các thiết bị chuyên nghiệp.
- Tiêu đề dường như mô tả nó như một bản sao chức năng, thay vì một bản sao hạn chế.
- Dự án này không phải là một bản sao, mà là một “demake” (phiên bản làm lại tệ hơn).
- Hiện tại dự án này chỉ là một cuộc tấn công replay, nhưng có thể được cải thiện trong tương lai.
MCP-B: Một Giao Thức cho Tự Động Hóa Trình Duyệt AI #
MCP-B: A Protocol for AI Browser Automation
MCP-B (Model Context Protocol for the Browser) là một loại công nghệ tự động hóa trình duyệt mới, cho phép trí tuệ nhân tạo (AI) tương tác trực tiếp với các chức năng của trang web, thay vì mô phỏng các thao tác của người dùng (như đọc màn hình và nhấp vào nút). Dưới đây là bản tóm tắt chi tiết về MCP-B:
1. Thực thi nhanh chóng #
MCP-B cho phép trợ lý AI hoàn thành nhiệm vụ với tốc độ tính bằng mili giây, trong khi tự động hóa trình duyệt truyền thống thường mất từ 10 đến 20 giây. Thông qua các lệnh gọi API trực tiếp, MCP-B tăng đáng kể hiệu quả thực thi.
2. Không cấu hình #
Chỉ cần thêm khoảng 50 dòng code, trang web có thể trở nên hỗ trợ AI. Không giống như OAuth 2.1 và khóa API truyền thống vốn đòi hỏi cấu hình phức tạp, MCP-B không cần những thứ đó, mà sử dụng xác thực trình duyệt hiện có.
3. Máy chủ MCP nhúng #
Máy chủ MCP được nhúng vào trang web, thay vì chạy như một tiến trình độc lập hoặc dịch vụ đám mây. Điều này làm cho máy chủ MCP trở thành một phần của ứng dụng Web, đơn giản hóa quy trình xác thực.
4. An ninh #
MCP-B tôn trọng các mô hình quyền hiện có, sử dụng phiên trình duyệt để xác thực, tránh các triển khai OAuth 2.1 phức tạp và quản lý khóa API, đảm bảo tính bảo mật.
5. Quy trình thực hiện #
- Máy chủ MCP (Tab): Sử dụng TypeScript và truyền bộ nhớ, gói các API đã được xác thực, tận dụng Cookies/JWT hiện có.
- Tiện ích mở rộng MCP-B: Kết nối với máy chủ tab thông qua content scripts, tập hợp tất cả các công cụ và quản lý kết nối.
- MCP Client: Sử dụng cầu nối cục bộ và các tùy chọn máy chủ proxy, cho phép AI yêu cầu các công cụ và trả về kết quả.
6. So sánh ưu điểm #
So với tự động hóa trình duyệt truyền thống, MCP-B có hiệu suất và độ tin cậy cao hơn. Các phương pháp truyền thống dựa vào phân tích màn hình, dễ bị ảnh hưởng bởi các thay đổi UI, trong khi MCP-B tránh được những vấn đề này bằng cách truy cập trực tiếp vào dữ liệu cấu trúc và API.
7. Thân thiện với người dùng #
MCP-B cung cấp trải nghiệm đơn giản hơn cho người dùng cuối, không cần quản lý API key hoặc cấu hình OAuth, mà chạy trực tiếp trong trình duyệt.
8. Khả năng mở rộng #
MCP-B đóng vai trò như một nền tảng mở rộng, các tiện ích mở rộng AI khác có thể kết nối với MCP-B và tận dụng các chức năng mà nó cung cấp.
9. Các trình duyệt được hỗ trợ #
Tiện ích mở rộng trình duyệt MCP-B tương thích với Chrome, Edge và Firefox, cung cấp cho người dùng một giải pháp đa trình duyệt.
10. Bắt đầu sử dụng #
Người dùng chỉ cần cài đặt tiện ích mở rộng từ Chrome Web Store, cấu hình nhà cung cấp AI của mình, là có thể bắt đầu quy trình làm việc tự động.
Tóm lại, MCP-B thúc đẩy tương lai của tự động hóa trình duyệt thông qua việc đơn giản hóa quy trình thiết lập, nâng cao hiệu suất và bảo mật, giúp trợ lý AI có thể tương tác hiệu quả hơn với các ứng dụng Web.
HN | Độ nóng: 322 điểm | 166 bình luận | Tác giả: bustodisgusto #
https://news.ycombinator.com/item?id=44515403
- MCP có thể bị các công ty kiểm soát giống như RSS, người dùng không thể hoàn toàn kiểm soát cách dữ liệu được sử dụng
- REST API và MCP về bản chất không phải là một, MCP giống JSON-RPC hơn, có các phương thức được liệt kê và ký
- REST API không hề biến mất, mà đã trở thành một cơ chế phân tách frontend và backend
- API HATEOAS thực sự khó xây dựng, tính thực tế của API điều hướng tự động còn hạn chế
- API chủ yếu là phương thức hợp tác giữa các doanh nghiệp, không thực tế đối với người dùng thông thường
- RSS vẫn tồn tại rộng rãi, nhiều trang web vẫn hỗ trợ RSS, mặc dù một số chỉ cung cấp một phần nội dung
- Số lượng người dùng trình đọc RSS giảm, nhưng bản thân công nghệ này vẫn được hỗ trợ và sử dụng rộng rãi
- Nhiều trang web cung cấp RSS chỉ chứa tiêu đề và tóm tắt bài viết, nhằm mục đích dẫn dắt người dùng nhấp vào quảng cáo
- RSS luôn là một thị trường ngách, các công ty ngừng đầu tư nguồn lực vì số lượng người dùng ít
- Một số nền tảng truyền thông xã hội tích hợp chức năng RSS, RSS không phải là một thị trường ngách
- RSS bị các công ty cố tình loại bỏ vì họ không thể thu được lợi nhuận từ nó
Sự tàn lụi của tiệc tùng ở Mỹ #
The death of partying in the USA
https://www.derekthompson.org/p/the-death-of-partying-in-the-usaand
Bài viết này được viết bởi Derek Thompson, chủ đề là khám phá hiện tượng giảm các hoạt động xã hội của giới trẻ Mỹ, đặc biệt là các hoạt động tiệc tùng, cũng như lý do đằng sau sự thay đổi này và tại sao nó lại quan trọng.
Bài viết bắt đầu bằng cách trích dẫn bài viết của Ellen Cushing trên tờ The Atlantic, chỉ ra rằng theo dữ liệu từ Khảo sát Sử dụng Thời gian của Hoa Kỳ (ATUS), năm 2023 chỉ có 4,1% người Mỹ cho biết họ “tham gia hoặc tổ chức” các bữa tiệc hoặc nghi lễ vào một ngày cuối tuần hoặc ngày lễ điển hình, có nghĩa là chỉ có một trong số 25 hộ gia đình Mỹ có kế hoạch tham gia các hoạt động xã hội. ATUS là một bảng câu hỏi của chính phủ, hỏi một số lượng lớn người Mỹ về cách họ phân bổ thời gian, bao gồm ngủ, làm việc, ăn mặc, chơi với thú cưng và tham gia các bữa tiệc, v.v. Ước tính ATUS mới nhất cho thấy thời gian người Mỹ tham gia hoặc tổ chức các hoạt động xã hội đã giảm 50% từ năm 2003 đến năm 2024, gần như mọi lứa tuổi đều giảm một nửa thời gian tiệc tùng, trong khi những người trẻ tuổi từ 15 đến 24 tuổi giảm nhiều hơn, lên đến 70%.
Thompson quy hiện tượng này vào một hiện tượng xã hội rộng lớn hơn mà ông gọi là “thế kỷ phản xã hội”. Trong thời đại lo lắng và rối loạn tâm lý gia tăng này, người Mỹ cô đơn hơn bất kỳ thời điểm nào trong lịch sử. Các hoạt động xã hội trực tiếp đã giảm khoảng 20% trong hai thập kỷ qua, và đối với nam giới chưa kết hôn và những người dưới 25 tuổi, sự sụt giảm này vượt quá 35%, điều này có thể giải thích tại sao những nhóm này dường như có ít bạn bè hơn bao giờ hết.
Bài viết cũng đề cập đến một số thống kê đáng kinh ngạc, chẳng hạn như thời gian nam giới xem TV gấp 7 lần thời gian giao tiếp xã hội với người ngoài, và phụ nữ nuôi thú cưng tương tác với thú cưng của họ nhiều hơn thời gian tiếp xúc trực tiếp với bạn bè là con người. Kể từ đầu những năm 2000, người Mỹ cho biết họ dành ít hơn một phần ba thời gian để giúp đỡ hoặc chăm sóc những người không phải là thành viên trực hệ trong gia đình.
Thompson cho rằng sự biến mất của các bữa tiệc, giống như thế kỷ phản xã hội, là do một loạt các yếu tố phức tạp gây ra, bao gồm kinh tế lao động, động lực gia đình, công nghệ tiêu dùng và tâm lý học hiện đại. Ông đề cập rằng phụ nữ từ lâu đã là người giữ gìn lịch xã hội của gia đình, nhưng đến nửa sau của thế kỷ 20, nhiều phụ nữ đã chuyển từ công việc gia đình không lương sang các vị trí được trả lương. Năm 1970, tỷ lệ tham gia lực lượng lao động của phụ nữ lần đầu tiên vượt quá 50% và hiện gần 80%. Khi ngày càng có nhiều phụ nữ dành ngày làm việc cho công việc từ 9 giờ sáng đến 5 giờ chiều, nam giới đã không tiếp quản công việc hậu cần cần thiết để lấp đầy lịch xã hội, và các buổi tụ tập của người lớn dần dần giảm đi trong thời đại các gia đình có hai nguồn thu nhập. Đồng thời, các quy tắc nuôi dạy con cái cũng đã thay đổi. Người Mỹ trước đây có nhiều con nhưng ít trông nom, bây giờ có ít con hơn nhưng trông nom nhiều hơn. Các bậc cha mẹ lo lắng hơn trước đây, không chỉ lo lắng về tội phạm khu phố và tai nạn sân chơi, mà còn lo lắng về thành tích của con cái.
Bài viết cuối cùng chỉ ra rằng kể từ năm 1970, sự gia tăng của chủ nghĩa cá nhân và cảm giác cô đơn là toàn diện. Hầu như tất cả các thước đo về đoàn kết xã hội đều bị ảnh hưởng, bao gồm tỷ lệ đi nhà thờ, sự tham gia công đoàn và các giải đấu bowling. Mặc dù một số nhà phê bình khăng khăng cho rằng mọi hiện tượng xã hội đều là một câu chuyện về giai cấp, nhưng Putnam đã chứng minh rằng những xu hướng này ảnh hưởng đến cả người giàu và người nghèo. Ông nói, dù có chuyện gì xảy ra, nó cũng xảy ra với tất cả chúng ta.
HN | Độ nóng: 312 điểm | 585 bình luận | Tác giả: tysone #
https://news.ycombinator.com/item?id=44514550
- Mạng xã hội, điện thoại thông minh và việc sắp xếp/bảo vệ quá mức đang phá hủy đời sống xã hội của nhiều người trẻ.
- Các bài đăng của Gen Z trên Reddit và Twitter mang tính thiên vị vì chúng hướng tới những Gen Z thường xuyên trực tuyến và sử dụng mạng xã hội nhiều.
- Việc sắp xếp quá mức là vấn đề lớn nhất mà thanh thiếu niên phải đối mặt, nhiều người gần như tối nào cũng có hoạt động.
- Nhu cầu về các hoạt động thể thao của thanh thiếu niên đã vượt khỏi tầm kiểm soát đối với trẻ em và gia đình, đặc biệt là các giải đấu tư nhân/câu lạc bộ.
- Một số gia đình coi các hoạt động thể thao là một gánh nặng không thể tránh khỏi, nhưng thực tế đó là do họ tự áp đặt.
- Các hoạt động thể thao của trường học hoặc đội cộng đồng là một sự thỏa hiệp giữa thể thao du lịch/câu lạc bộ và việc không tham gia thể thao.
- Một số trường yêu cầu học sinh tham gia đội du lịch từ khi còn học tiểu học, nếu không sẽ không thể chơi trong đội trường chính quy.
- Xu hướng các trường trung học lớn dẫn đến việc giảm cơ hội tham gia các hoạt động thể thao, vì trường quá lớn và số lượng vị trí trong đội có hạn.
- Hỗ trợ con bạn theo đuổi hành trình của riêng mình trong thể thao và hãy nhớ rằng điều quan trọng nhất trong thể thao không chỉ là màn trình diễn trên sân.
Gemini 2.5 có giỏi trong việc xác định bounding box không? #
Is Gemini 2.5 good at bounding boxes?
https://simedw.com/2025/07/10/gemini-bounding-boxes/
Blog của SimEdw đã đăng một bài viết vào ngày 10 tháng 7 năm 2025 về hiệu suất của Gemini 2.5 Pro trong nhiệm vụ phát hiện đối tượng. Bài viết bắt đầu bằng một câu hỏi: Liệu các mô hình ngôn ngữ lớn đa phương thức đã sẵn sàng thay thế các mạng nơ-ron tích chập (CNNs) trong các nhiệm vụ thị giác máy tính chưa? Tác giả bị cám dỗ bởi việc bỏ qua quá trình thu thập, chú thích và huấn luyện dữ liệu, quyết định thực hiện benchmark Gemini 2.5 trên bộ dữ liệu MS-COCO.
Bài viết mô tả chi tiết về bộ dữ liệu MS-COCO, một bộ dữ liệu phát hiện đối tượng cổ điển, bao gồm 80 danh mục, từ người đến bàn chải đánh răng. Mặc dù ranh giới đối tượng đôi khi có thể mơ hồ, nhưng sự mơ hồ này sẽ triệt tiêu lẫn nhau trong toàn bộ tập dữ liệu. Tập hợp xác thực chứa 5000 hình ảnh, mặc dù về mặt lý thuyết không nên được sử dụng để huấn luyện, nhưng không thể đảm bảo rằng Gemini chưa tiếp xúc với những hình ảnh này trong quá trình huấn luyện.
Tác giả đã sử dụng một prompt cụ thể trong thử nghiệm, nhúng danh sách các danh mục hợp lệ của MS-COCO vào prompt và yêu cầu nó tuân theo lược đồ đầu ra JSON. Để tránh Gemini tiếp xúc với bộ dữ liệu COCO trong quá trình huấn luyện, tác giả cố ý không đề cập rõ ràng đến tên COCO. Prompt yêu cầu mô hình xem xét kỹ hình ảnh và phát hiện tất cả các đối tượng hiển thị, bao gồm các đối tượng nhỏ, ở xa hoặc hiển thị một phần, đồng thời đảm bảo rằng các hộp giới hạn càng chặt càng tốt. Đối với mỗi đối tượng được phát hiện, mô hình cần cung cấp tên danh mục, độ tin cậy, tọa độ hộp giới hạn 2D được chuẩn hóa và mặt nạ nhị phân của đối tượng.
Bài viết tiếp tục thảo luận về phương pháp tính toán độ chính xác trung bình (mAP) trong phát hiện đối tượng, tức là giá trị trung bình của độ chính xác trung bình mà mô hình dự đoán trên nhiều ngưỡng chồng lấp (IoU). Tác giả cung cấp một số mã giả để giúp hiểu quy trình tính toán mAP.
Trong phần kết quả, bài viết trình bày rõ ràng sự so sánh hiệu suất giữa các mô hình và cài đặt khác nhau. Gemini Pro trong đầu ra có cấu trúc hoạt động tốt hơn các phiên bản Flash và Flash-Lite. Việc tăng ngân sách suy nghĩ sẽ làm giảm đáng kể hiệu suất. Đối với phiên bản Pro, việc không sử dụng ngân sách suy nghĩ sẽ cho kết quả tốt hơn. Phiên bản Pro cũng hoạt động tốt hơn trong việc tránh trả về các đầu ra không hợp lệ.
Cuối cùng, bài viết kết luận rằng mặc dù CNNs được huấn luyện rõ ràng cho 80 danh mục này, nhưng Gemini 2.5 Pro đã hoạt động xuất sắc trong benchmark. Mặc dù các hộp giới hạn có thể lỏng lẻo hơn, nhưng chúng có thể được tinh chỉnh bằng các mô hình phân đoạn như SAM. Mặc dù CNNs nhanh hơn, rẻ hơn và dễ hiểu hơn khi có dữ liệu huấn luyện tốt, nhưng tính linh hoạt của Gemini trong các nhiệm vụ tập mở gần như kỳ diệu. Tác giả cho biết, anh ấy sẽ sử dụng Gemini trong các dự án tương lai.
Bài viết cuối cùng đề cập đến nghiên cứu liên quan của Simon Willison và khuyên độc giả nên xem các công cụ trực quan hóa và bài đăng trên blog của anh ấy. Nó cũng đề cập đến một bài báo so sánh hiệu suất của các mô hình lớn khác nhau trong các nhiệm vụ thị giác, nhưng thay vì chỉ đơn giản là nhắc tọa độ hộp giới hạn, chúng sử dụng phương pháp “thu phóng đệ quy”, chia hình ảnh thành các ô lưới và hỏi mô hình xem mỗi lưới có chứa một phần của đối tượng hay không. Sau đó, thao tác này được thực hiện đệ quy trên các lưới chứa đối tượng. Điều này khác với benchmark của tác giả, vốn hỏi tất cả các đối tượng cùng một lúc.
HN | Độ nóng: 252 điểm | 55 bình luận | Tác giả: simedw #
https://news.ycombinator.com/item?id=44520292
- Các mô hình Google từ Gemini 2.0 trở lên đều đã được huấn luyện hậu kỳ cho nhiệm vụ phát hiện hộp giới hạn
- Mô hình Gemini được tối ưu hóa cao cho định dạng
box_2d, ngay cả những thay đổi nhỏ về định dạng cũng có thể dẫn đến giảm hiệu suất - Mô hình Gemini hoạt động xuất sắc trong các nhiệm vụ đa phương thức, bao gồm phân đoạn hình ảnh
- Huấn luyện hậu kỳ có thể tận dụng sự hiểu biết của mô hình được huấn luyện trước về thế giới và ngôn ngữ để cải thiện hiệu suất
- Do sự khác biệt lớn về hiệu suất của các mô hình ngôn ngữ thị giác (VLMs) khác nhau trong nhiệm vụ phát hiện đối tượng, nên không thể đơn giản hoán đổi các mô hình để có được kết quả tương tự
- Một số VLMs vẫn hoạt động kém trong việc định vị ngay cả sau khi được huấn luyện hậu kỳ
- Gemini sử dụng một hệ tọa độ cụ thể (ymin, xmin, ymax, xmax) để huấn luyện hậu kỳ, trong khi các mô hình khác có thể sử dụng các hệ tọa độ khác nhau
- Chọn ủy thác nhiệm vụ phát hiện đối tượng cho các công cụ chuyên dụng vì hiệu suất của VLMs tương đối kém
- Gemini 2.5 có hiệu suất không đồng đều trên các tập dữ liệu phát hiện đối tượng mã nguồn mở, đặc biệt là trên dữ liệu ngoài phân phối
- Gemini 2.5 hoạt động tốt trong học không mẫu, nhưng hiệu suất giảm khi cung cấp ví dụ trực quan hoặc hướng dẫn bằng văn bản
- Gemini hoạt động xuất sắc trong nhiệm vụ phát hiện hộp giới hạn PDF
- Đối với các tài liệu PDF không có văn bản nhúng, việc sử dụng Gemini để phát hiện hộp giới hạn có thể không đủ ổn định
- Tăng bộ đệm có thể giúp giải quyết các vấn đề về định vị hộp giới hạn không chính xác
- Các mô hình ngôn ngữ thị giác (LLMs) mã hóa hình ảnh thành token và xử lý chúng thông qua bộ mã hóa thị giác, thay vì chỉ đơn giản gọi API của một mô hình thị giác khác
- Hầu hết các LLMs thị giác không sử dụng mô hình thị giác riêng biệt, mà tích hợp xử lý thị giác và ngôn ngữ với nhau
Phân loại các từ ngữ đặc trưng Canada #
A Typology of Canadianisms
https://dchp.arts.ubc.ca/how-to-use
Ấn bản thứ ba của Từ điển các Nguyên tắc Lịch sử Tiếng Anh Canada (DCHP-3) là một từ điển chuyên biệt thu thập các từ vựng tiếng Anh Canada, nó giải thích chi tiết các từ và cách sử dụng đặc trưng của tiếng Anh Canada. Cấu trúc của từ điển này về cơ bản giống với phiên bản trước (DCHP-2), nhưng có sự khác biệt về hình thức bên ngoài.
Mỗi mục từ (headwords, lexemes) trong từ điển được phân loại theo sáu loại tiếng Anh Canada, hoặc được đánh dấu là “phi Canada” (Non-Canadian). Sáu loại này bao gồm:
- Loại Nguồn gốc (Type 1): Các hình thức và ý nghĩa được tạo ra ở Canada, ví dụ như “garburator” (máy xử lý rác thải).
- Loại Bảo tồn (Type 2): Các hình thức hoặc ý nghĩa tiếng Anh từng được sử dụng rộng rãi nhưng được bảo tồn trong tiếng Anh Canada, ví dụ như “pencil crayon” (bút chì màu).
- Loại Biến đổi Ngữ nghĩa (Type 3): Các hình thức có sự thay đổi về ngữ nghĩa trong tiếng Anh Canada, ví dụ như “toque” (ban đầu chỉ mũ đầu bếp hoặc mũ phụ nữ, sau chỉ mũ len giữ ấm ôm sát đầu).
- Loại Nổi bật về Văn hóa (Type 4): Các hình thức hoặc ý nghĩa có vị trí nổi bật trong văn hóa Canada, ví dụ như các thuật ngữ liên quan đến “hockey” (khúc côn cầu trên băng).
- Loại Tần suất (Type 5): Các hình thức hoặc ý nghĩa được coi là tiếng Anh Canada do tần suất sử dụng cao ở Canada, ví dụ như “washroom” (nhà vệ sinh).
- Loại Tưởng niệm (Type 6): Các hình thức hoặc ý nghĩa liên quan đến mặt tối trong lịch sử Canada, ví dụ như “residential school” (trường nội trú).
Cấu trúc của mỗi mục từ tuân theo trình tự của DCHP-2, bên trái hiển thị các ý nghĩa và siêu liên kết có sẵn, dấu thời gian ở góc trên bên phải xác định phiên bản của mục từ và ngày tạo lần đầu. Các đoạn trích dẫn tiếp tục bên dưới mỗi ý nghĩa, các trích dẫn phi Canada được đánh dấu bằng “dao găm” để hiểu ngữ cảnh. Các trích dẫn đến từ các nguồn của Canada hoặc người nói tiếng Canada, nhấp vào biểu tượng cuốn sách để xem thông tin thư mục chi tiết và nếu có, sẽ cung cấp siêu liên kết đến nguồn.
Các trích dẫn trong ngoặc vuông được sử dụng cho hai mục đích: bao gồm các trích dẫn phi Canada, chẳng hạn như “atmospheric river” (sông khí quyển) từ các nguồn của Hoa Kỳ; hoặc trong những trường hợp rất hiếm, để cung cấp các trích dẫn bằng tiếng nước ngoài để hiểu ngữ cảnh, chẳng hạn như “quadrex” (bộ tứ).
Trong ví dụ về “stagette” (tiệc độc thân của phụ nữ), sau khi kết thúc đoạn trích dẫn, tiếp theo là phần tài liệu tham khảo và hình ảnh. Bất kỳ nguồn nào được đề cập sẽ được cung cấp ở đây và nếu có, sẽ được liên kết. Cuối cùng, tất cả các hiệu ứng hình ảnh (ví dụ: biểu đồ tần suất và hình ảnh) được đề cập trong “Word Story” và các văn bản biên tập khác (ví dụ: chú thích) sẽ được liệt kê.
Biểu đồ tần suất tuân theo mô hình đã được thiết lập, sử dụng “the” làm từ tìm kiếm, điều này đã được chứng minh là đáng tin cậy hơn so với việc sử dụng động từ tình thái “could”. Từ tìm kiếm chính xác luôn được hiển thị trong tiêu đề biểu đồ. Các từ vựng nhiều phần luôn được tìm kiếm bằng dấu ngoặc kép, ví dụ: biểu đồ của “were dinged” (bị chỉ trích) được tạo bằng cách nhập “were dinged” site:.ca, sau đó là các tìm kiếm trang web khác, chẳng hạn như site:.edu. Trong trường hợp này, biểu đồ tần suất của “ding” có thể phân biệt nhiều ý nghĩa khác nhau và cô lập ý nghĩa duy nhất có vị thế Canada.
Do tính đa nghĩa của một số thuật ngữ, đôi khi bằng cách thêm hoặc loại trừ các từ tìm kiếm, hoặc sử dụng các cụm từ chuyên biệt hơn để thu hẹp phạm vi tìm kiếm, các cụm từ này được sao chép bằng dấu ngoặc kép, ví dụ: “buy on tick” (mua chịu) hoặc “off-reserve population” (dân số ngoài khu bảo tồn). Việc thu hẹp phạm vi tìm kiếm được quyết định bằng cách đọc các trích dẫn và quyết định xem nó chỉ tạo ra ý nghĩa mục tiêu hay gần như chỉ tạo ra ý nghĩa mục tiêu. Từ điển không giải thích tại sao sử dụng một tổ hợp từ tìm kiếm nhất định thay vì một tổ hợp khác, vì một cuộc thảo luận như vậy có thể quá phức tạp và dài dòng.
HN | Độ nóng: 246 điểm | 305 bình luận | Tác giả: gnabgib #
https://news.ycombinator.com/item?id=44515101
- Từ “Canada” bắt nguồn từ ngôn ngữ Iroquois, ban đầu được các nhà thực dân Pháp sử dụng để chỉ người bản địa
- Từ “Canada” ban đầu được nhà thám hiểm Jacques Cartier sử dụng để chỉ thành phố mà ngày nay được gọi là “Quebec”
- Sau cuộc xâm lược của Anh, từ “Canada” bắt đầu được sử dụng để chỉ First Nations và những người định cư Pháp (mang tính miệt thị)
- Theo thời gian, từ “Canada” thường được sử dụng để chỉ cư dân Canada
- Đội khúc côn cầu “Les Canadiens” của Montreal là đội khúc côn cầu lâu đời nhất ở Canada, tên gọi là sự tái sử dụng từ “Canada”
- Từ “tỉnh” có nguồn gốc từ tiếng Latinh, được người La Mã sử dụng để mô tả các vùng lãnh thổ bị chinh phục
- Những người sáng lập Canada đã quyết định sử dụng “tỉnh” thay vì “bang” vào năm 1867
- Những người quan tâm đến lịch sử Canada nên xem các trang Wikipedia phiên bản tiếng Pháp
- Việc người Anh chọn một từ tiếng Pháp mà những người bị chinh phục có thể hiểu được là điều hợp lý
- Từ “tỉnh” làm rõ lòng trung thành với vương miện ở nước ngoài
- “Lãnh thổ tự trị” là một thuật ngữ rõ ràng hơn để thể hiện lòng trung thành với vương miện ở nước ngoài
- Hầu hết tất cả các từ tiếng Anh liên quan đến chính phủ/luật pháp/hành chính đều có nguồn gốc từ tiếng Pháp
- Tiếng Norman Pháp được sử dụng làm ngôn ngữ hành chính ở Anh trong khoảng 300 năm
- “Dominion Canada” thực chất là tên của một công ty đường sắt
- Tây Canada, các tỉnh ven biển và người dân Quebec đều có một số hình thức xa lánh
- Tỉnh Quebec có luật ngôn ngữ rất nghiêm ngặt nhằm bảo vệ tiếng Pháp
- Cộng đồng Pháp ngữ ở Quebec trục xuất cộng đồng nói tiếng Anh bằng cách tấn công ngôn ngữ, văn hóa, giáo dục và việc làm của họ
- Dân số nói tiếng Anh ở Quebec chiếm 10%, có 3 trường đại học, bao gồm Đại học McGill, cũng như các nhà hát, nghệ sĩ, báo chí và chương trình truyền hình
Một thư viện công cộng ở Virginia đang chống lại sự tiếp quản bởi quỹ đầu tư tư nhân #
A Virginia public library is fighting off a takeover by private equity
Một thư viện công cộng ở Virginia đang chống lại sự tiếp quản bị đe dọa bởi vốn cổ phần tư nhân.
Thư viện Công cộng Samuels ở Front Royal, Virginia, sau khi bị nhắm mục tiêu và rút vốn bởi những người giăng biểu ngữ chống LGBTQ, đã thành công trong việc ngăn chặn một vụ tiếp quản bị đe dọa bởi một tập đoàn vốn cổ phần tư nhân. Cộng đồng địa phương đã đoàn kết để ủng hộ Thư viện Công cộng Samuels, phản đối các cuộc tấn công, và Library Systems & Services (LS&S), một công ty dịch vụ và hệ thống thư viện thuộc sở hữu của vốn cổ phần tư nhân, đã rút lại hồ sơ dự thầu để vận hành thư viện. Nhưng với việc tài trợ của họ bị cắt giảm bắt đầu từ tháng 7 năm tài chính này, thư viện hiện đang ở trong một tình huống bấp bênh.
Thư viện Công cộng Samuels gần như đã trải qua toàn bộ lịch sử Hoa Kỳ; nó được thành lập vào năm 1799, là thư viện lâu đời thứ hai ở Virginia. Thư viện được đổi tên thành Samuels vào những năm 50 và gần đây hoạt động như một tổ chức phi lợi nhuận hợp tác với chính quyền địa phương. Hồ sơ dịch vụ của nó rất ấn tượng: nó đã giành được giải thưởng Thư viện của năm của Virginia năm 2024 và theo Royal Examiner địa phương, năm ngoái nó đã thêm 2204 người đăng ký thẻ mới, tổ chức 542 chương trình và có 401859 lượt mượn.
Rắc rối gần đây của thư viện bắt đầu vài năm trước khi Samuels trở thành mục tiêu của một nhóm người muốn loại bỏ sách thiếu nhi khỏi kệ. Năm 2023, “Clean Up Samuels” đã đệ trình hàng trăm đơn khiếu nại về những cuốn sách mà họ không thích, phần lớn là những cuốn sách có chủ đề LGBTQ. Một thành viên của nhóm nói với Associated Press rằng những lời phàn nàn của họ bắt nguồn từ mối quan tâm của người nộp thuế về “quyền tự chủ”, điều này thật trớ trêu vì cuộc chiến cuối cùng đã kết thúc bằng việc cố gắng thuê ngoài việc quản lý thư viện cho một công ty tư nhân, vì lợi nhuận.
Đứng về phía những người giăng biểu ngữ sách, các quan chức Quận Warren địa phương đã bỏ phiếu giữ lại tiền tài trợ cho thư viện. Samuels kiên quyết phản đối kiểm duyệt và cuối cùng tiền của họ đã được khôi phục. Nhưng vào tháng 3 năm nay, Hội đồng Giám sát Quận Warren đã bỏ phiếu chống lại việc gia hạn tài trợ hàng năm, viện dẫn việc quản lý yếu kém và tuyên bố rằng họ có ý định đưa LS&S từ bên ngoài vào để vận hành thư viện.
LS&S không xa lạ gì với việc gây ra những cuộc chiến cộng đồng này. Một tìm kiếm trên Google về công ty này sẽ tìm thấy rất nhiều bài báo và bình luận phản đối việc tiếp quản thư viện địa phương, báo cáo kiện tụng và các bài đăng trên Reddit cảnh báo các thủ thư nên cẩn thận khi làm việc cho họ. LS&S bắt đầu xây dựng phần mềm quản lý danh mục vào những năm 80 và giành được các hợp đồng của chính phủ với các cơ quan liên bang khi Reagan thúc đẩy tư nhân hóa phần lớn hoạt động của chính phủ liên bang. Ngày nay, họ thuộc sở hữu của Evergreen Services Group, một công ty vốn cổ phần tư nhân sở hữu nhiều công ty con, nhiều công ty trong số đó hoạt động trong lĩnh vực gia công phần mềm cho chính phủ và quốc phòng.
The Times đã đưa tin về công ty này vào năm 2010 khi nó được đưa vào để quản lý các thư viện ở California và đã phát triển thành “hệ thống thư viện lớn thứ năm” ở Hoa Kỳ. Trong bài viết, cựu Giám đốc điều hành của LS&S, Frank A. Pezzanite, đã sử dụng hiệu quả và tinh giản để mô tả công việc của mình, điều này có nghĩa là cắt giảm đáng kể:
“Thư viện có một thứ gì đó như cờ Mỹ, bánh táo,” Frank A. Pezzanite, Giám đốc điều hành của công ty gia công phần mềm cho biết. Ông đã hứa sẽ tiết kiệm 1 triệu đô la mỗi năm cho Santa Clarita, chủ yếu bằng cách cắt giảm chi phí và thay thế nhân viên công đoàn. “Bằng cách nào đó, chúng được phân loại là một tổ chức thiêng liêng.”
“Rất nhiều thư viện đều tồi tệ,” ông Pezzanite nói. “Chính sách của họ là về sự đảm bảo công việc. Đó là lý do tại sao ngành này lo lắng về chúng tôi. Bạn có thể làm việc trong thư viện 35 năm và sau đó nghỉ hưu. Chúng tôi không điều hành công ty của mình theo cách đó. Bạn đến với chúng tôi, bạn phải làm việc.”
Cuối cùng, có một công ty dũng cảm đứng lên chống lại các thủ thư.
Tôi rất vui vì Samuels đã có thể đẩy lùi LS&S, nhưng sự cố này là một ví dụ khác về cách logic thị trường toàn diện của thương mại có thể hợp tác với những tác nhân trừng phạt bên trong chính phủ. Khi bạn không thể khiến mọi người ủng hộ các kế hoạch thay đổi dịch vụ công, một công ty tư nhân có thể vào và tinh giản chúng đến chết.
Để biện minh cho họ, tôi nghĩ một số doanh nghiệp này nghĩ rằng họ đang làm điều đúng đắn. Nhưng sự tập trung vào lợi nhuận khiến họ không thể thấy lợi ích công cộng là một điểm mấu chốt xứng đáng. Phục vụ cộng đồng có thể không có lợi nhuận, nhưng điều đó không có nghĩa là nó sai.
Tôi nhớ đến một cuộc phỏng vấn trên NPR với một nhân viên DOGE thất vọng, người đã không tìm thấy một ổ tham nhũng và lười biếng trong chính phủ liên bang. “Chính phủ thực sự không lãng phí,” anh nói.
Chính phủ cam kết làm rất nhiều điều cho công dân của mình, và thường thì nó thực hiện khá tốt, đầy những người tuyệt vời, siêng năng, có học thức. Nó có quá tốt với những người này không? Có lẽ. Nó có quá tốt với công dân không? Có lẽ. Nó có thể hoạt động hiệu quả hơn không? Có thể. Nhưng hiệu quả có phải luôn là mục tiêu không? Không, tôi không biết.
Hiệu quả không phải lúc nào cũng nên là mục tiêu, đặc biệt khi nó được sử dụng như một phép ẩn dụ hẹp hòi cho khả năng sinh lời. Một tổ chức công cộng như Thư viện Công cộng Samuels hoạt động hiệu quả vì nó phục vụ một thứ gì đó vượt ra ngoài tiền bạc.
Nếu bạn muốn ủng hộ Samuels trong cuộc chiến giành lại nguồn tài trợ của họ, bạn có thể quyên góp trên trang web của họ.
HN | Độ nóng: 243 điểm | 209 bình luận | Tác giả: sharkweek #
https://news.ycombinator.com/item?id=44516793
- Tối đa hóa lợi nhuận thường đi ngược lại với phúc lợi của con người và sự thịnh vượng của xã hội, ví dụ như các công ty bảo hiểm y tế kiếm lợi nhuận bằng cách từ chối yêu cầu bồi thường, dẫn đến hệ thống bảo hiểm đắt đỏ và kết quả sức khỏe kém hơn.
- Tham lam chứ không phải lợi nhuận mới là vấn đề, chính sách của chính phủ cũng không hoàn toàn vị tha, mà là thông qua các dự án công cộng như giáo dục và bảo hiểm y tế để giảm chi phí cho người sử dụng lao động, nâng cao trật tự xã hội và lợi nhuận.
- Bài học của thế kỷ 20 đã bị lãng quên, lợi nhuận không nên chỉ được xem là con số trên báo cáo tài chính, mà nên phản ánh lợi ích lâu dài.
- Bản chất con người (tham lam) không thể thay đổi, nên thiết kế các thể chế để hướng bản chất con người theo hướng có lợi, đồng thời kiểm soát các tác dụng phụ của nó.
- Chủ nghĩa tư bản là một nỗ lực chưa hoàn chỉnh để biến lòng tham thành những thứ có lợi cho tất cả mọi người, nhưng thất bại thị trường là rất phổ biến, cần có nền kinh tế hỗn hợp và quy định thông minh.
- Hành vi do lòng tham gây ra có thể được kiểm soát thông qua luật pháp và cơ chế chính phủ, vấn đề là các giám đốc điều hành công ty hiếm khi bị trừng phạt vì hành vi có hại do lòng tham gây ra.
- Lập kế hoạch tập trung thất bại do vấn đề truyền tải thông tin và thiếu động lực cá nhân, nhưng hiện nay tiến bộ công nghệ khiến việc lập kế hoạch tập trung có thể không còn là vấn đề nữa.
- Trong chủ nghĩa tư bản, chính phủ không bị ảnh hưởng bởi tiền bạc là điều không thể, luôn có những cá nhân hoặc công ty đủ giàu có để gây ảnh hưởng đến chính phủ.
Show HN: Máy chủ MCP để tìm kiếm và tải xuống tài liệu từ Anna’s Archive #
Show HN: MCP server for searching and downloading documents from Anna’s Archive
https://github.com/iosifache/annas-mcp
Trang web này giới thiệu một dự án có tên “Anna’s Archive MCP Server (và công cụ CLI)”, nó là một máy chủ MCP và công cụ dòng lệnh (CLI) để tìm kiếm và tải xuống tài liệu từ Anna’s Archive.
Mô tả dự án: Dự án này cung cấp một máy chủ MCP và công cụ CLI để tìm kiếm và tải xuống tài liệu từ Anna’s Archive. Mặc dù công chúng có nhiều quan điểm khác nhau về Anna’s Archive, nhưng nền tảng này là một kho lưu trữ toàn diện để tự động truy xuất các tài liệu được xuất bản theo khuôn khổ cấp phép (bao gồm các ấn phẩm Creative Commons và tài liệu thuộc phạm vi công cộng). Phần mềm này không hỗ trợ việc thu thập trái phép nội dung được bảo vệ bản quyền và chỉ nên được coi là một công cụ hữu ích. Người dùng được khuyến khích tôn trọng quyền sở hữu trí tuệ của tác giả và thừa nhận những nỗ lực to lớn đã được đầu tư vào việc tạo ra tài liệu. Các thao tác khả dụng: - Tìm kiếm: Sử dụng thao tác “search” của công cụ MCP hoặc lệnh “search” của CLI để tìm kiếm các tài liệu trong Anna’s Archive khớp với các thuật ngữ được chỉ định.
- Tải xuống: Sử dụng thao tác “download” của công cụ MCP hoặc lệnh “download” của CLI để tải xuống các tài liệu cụ thể được trả về bởi công cụ tìm kiếm trước đó.
Yêu cầu: - Nếu bạn chỉ định sử dụng công cụ CLI, bạn cần quyên góp cho Anna’s Archive để có được quyền truy cập API JSON và khóa API.
Nếu bạn sử dụng dự án làm máy chủ MCP, bạn cũng cần một ứng dụng khách MCP, chẳng hạn như Claude Desktop.
Môi trường nên chứa hai biến:
ANNAS_SECRET_KEY(khóa API) vàANNAS_DOWNLOAD_PATH(đường dẫn mà tài liệu sẽ được tải xuống). Thiết lập: - Tải xuống các tệp nhị phân thích hợp từ phần GitHub Releases.Nếu bạn định sử dụng chức năng máy chủ MCP của công cụ, bạn cần tích hợp nó vào ứng dụng khách MCP của mình. Nếu bạn đang sử dụng Claude Desktop, bạn có thể xem xét cấu hình mẫu được cung cấp. Trình diễn: - Trình diễn như một máy chủ MCP.
Trình diễn như một công cụ CLI. Về: - Đây là một máy chủ MCP và công cụ CLI để tìm kiếm và tải xuống tài liệu từ Anna’s Archive.
URL là annas-archive.org.
Các chủ đề liên quan bao gồm cli, annas-archive và mcp-server. Tài nguyên: - Bạn có thể đọc tệp Readme của dự án để biết thêm thông tin. Hoạt động: - Dự án đã nhận được 280 sao và 8 nhánh. Phát hành: - Phiên bản mới nhất v0.0.2 được phát hành vào ngày 10 tháng 7 năm 2025. Ngôn ngữ:
Dự án chủ yếu sử dụng ngôn ngữ Go (82.8%) và Shell script (17.2%).
Phần cuối trang web chứa thông tin bản quyền của GitHub, các liên kết đến điều khoản, chính sách bảo mật, bảo mật, trạng thái, tài liệu, liên hệ và quản lý cookie.
HN | Độ nóng: 242 điểm | 74 bình luận | Tác giả: iosifache #
https://news.ycombinator.com/item?id=44514753
- Dự án này cho phép người dùng tìm kiếm và tải sách từ Anna’s Archive trực tiếp từ Claude Desktop.
- Máy chủ MCP cung cấp trải nghiệm người dùng tốt hơn và dân chủ hóa việc truy cập dữ liệu so với các công cụ dòng lệnh.
- Tích hợp MCP giúp người dùng không am hiểu kỹ thuật cũng có thể dễ dàng sử dụng các công cụ vốn phức tạp.
- Việc tạo máy chủ MCP có thể được hỗ trợ nguyên bản bởi thư viện API, vì sự trừu tượng của nó tương tự như API.
- Dự án này không chỉ đơn thuần là đơn giản hóa việc sử dụng Anna’s Archive cho con người, mà còn để các AI agent có thể tự động thu thập thông tin.
- MCP cung cấp một phương pháp tiêu chuẩn cho các AI agent để sử dụng các lệnh và chỉ thị, điều mà các công cụ CLI không có.
- Một số người cho rằng, sự phát triển của trí tuệ và khả năng tiếp cận kiến thức phổ quát quan trọng hơn so với lợi ích bản quyền.